
As a longtime [American Scientific Affiliation] member, I was obviously pleased to see Perspectives on Science and Christian Faith (PSCF) devote a review essay in its December 2010 issue to an assessment of my recent book, Signature in the Cell: DNA and the Evidence for Intelligent Design (HarperOne 2009). I also welcomed the general approach of PSCF’s designated reviewer, Dennis Venema. Unlike some critics, Venema at least attempted to assess the issues raised in Signature in the Cell by appealing to scientific evidence rather than merely dismissing the idea of intelligent design with pejorative labels (such as “scientific creationism”) or a priori philosophical judgments (such as “intelligent design is not science”).1
Nevertheless, Venema argued that the scientific evidence does not support my argument for intelligent design, and he offered several lines of evidence in an attempt to refute it. And, of course, I disagree with his arguments. In this response, I will show why. I will demonstrate that Venema did not refute the argument of Signature in the Cell and that he failed to do so for two main reasons:
The balance of his review is spent refuting an argument that Signature in the Cell does not make and, thus, the evidence he cites is irrelevant to the main argument of the book; in short, Venema “refutes” a straw man.
The relevant scientific proposals that Venema does cite as evidence against the thesis of the book are deeply flawed. In particular: (a) TRNA world hypothesis has not solved the problem of the origin of life or the origin of biological information. (b) The “direct templating” model of the origin of the genetic code fails to explain both the origin of the code and the origin of sequence-specific genetic information.
Let us consider each of these problems in turn.
Venema’s Straw Man
After beginning with a reasonably accurate (though incomplete) chapter-by-chapter summary of the argument of the book, Venema makes an abrupt disconnect with his own exposition and proceeds to critique an argument wholly different from the one he has just summarized. Whereas my book attempts to establish intelligent design as the best explanation for the information necessary to produce the first life, Venema critiques the claim that natural selection and random mutation cannot produce the information necessary to produce new forms of life from preexisting forms of life. While the book presents intelligent design as an alternative to chemical evolutionary theory, Venema critiques it as if it had presented a critique of neo-Darwinism — i.e., biological evolutionary theory.
To establish that Venema failed in the main to address my argument, it might be helpful to summarize the actual argument of Signature in the Cell for those who have not yet read it.
From the Horse’s Mouth: The Argument of Signature in the Cell
Signature in the Cell addresses what I call the “DNA Enigma,” the mystery of the information necessary to produce the first life. The book begins by describing this enigma and how it emerged from the revolutionary developments in molecular biology during the 1950s and 1960s. When Watson and Crick discovered the structure of DNA in 1953, they also discovered that DNA stores information in the form of a four-character alphabetic code. Strings of precisely sequenced chemicals called nucleotide bases store and transmit the assembly instructions — the information — for building the crucial protein molecules and protein machines the cell needs to survive. Crick later developed this idea with his famous “sequence hypothesis,” according to which the nucleotide bases in DNA function like letters in a written language or symbols in a computer code. Just as letters in an English sentence or digital characters in a computer program may convey information depending on their arrangement, so too do certain sequences of chemical bases along the spine of the DNA molecule convey precise instructions for building proteins.
Further, since life depends upon the presence of genetic information, any theory of the origin of the first life must provide an account of the origin of this information. As origin-of-life researcher Bernd-Olaf Küppers has explained, “The problem of the origin-of-life is clearly basically equivalent to the problem of the origin of biological information.”2
The book then draws an important distinction between the mathematical theory of information developed by Claude Shannon at MIT during the late 1940s and what has been called “functional information,”3 “specified information,” or “specified complexity.”4 According to Shannon, the amount of information conveyed in a series of symbols or characters is inversely proportional to the probability of a particular event, symbol, or character occurring. Functional or specified information, by contrast, is present in sequences in which the specific arrangement of the symbols or characters is crucial to the ability of the string to perform a function or convey meaning. For example, consider two sequences of characters:
Four score and seven years ago
nenen ytawoi jll sn mekhdx nnx
Both of these sequences have an equal number of characters. Since both are composed of the same 26-letter English alphabet, the probability of producing each of those two sequences at random is identical. Therefore, both sequences have an equal amount of information as measured by Shannon’s theory. Nevertheless, the first of these sequences performs a communication function, while the second does not.
When discussing information in a biological context, we must distinguish sequences of characters that are (a) merely improbable from (b) sequences that are improbable and also specifically arranged so as to perform a function. Following Francis Crick himself, I show that DNA-base sequences do not just possess “information” in the strictly mathematical sense of Shannon’s theory. Instead, DNA contains information in the richer and more ordinary sense of “alternative sequences or arrangements of characters that produce a specific effect.” DNA-base sequences convey assembly instructions. They perform functions in virtue of their specific arrangements. Thus, they do not possess mere “Shannon information,” but instead “specified” or “functional information.” Indeed, like the precisely arranged zeros and ones in a computer program, the chemical bases in DNA convey instructions in virtue of their “specificity.”
Having defined the kind of information that needs to be explained in any theory of the origin of the first life, the book then does two things.
First, it shows that historical scientists typically use a method of multiple competing hypotheses.5 Contemporary philosophers of science such as Peter Lipton have called this the method of “inference to the best explanation.” 6 That is, when trying to explain the origin of an event, feature, or structure in the remote past, scientists typically compare various hypotheses to see which would, if true, best explain it. 7 They then provisionally affirm the hypothesis that best explains the data as the one that is most likely to be true. But that raises a question: what makes an explanation best?
Historical scientists have developed criteria for deciding which cause, among a group of competing possible causes, provides the best explanation for some event in the remote past. The most important of these criteria is called “causal adequacy.” This criterion requires that historical scientists identify causes that are known to have the power to produce the kind of effect, feature, or event that requires explanation. In making these determinations, historical scientists evaluate hypotheses against their present knowledge of cause and effect. Causes that are known to produce the effect in question are judged to be better candidates than those that do not. For instance, a volcanic eruption provides a better explanation for an ash layer in the earth than an earthquake because eruptions have been observed to produce ash layers, whereas earthquakes have not.
One of the first scientists to develop this principle was the geologist Charles Lyell who also influenced Charles Darwin. Darwin read Lyell’s The Principles of Geology while onboard the Beagle and employed its principles of reasoning in The Origin of Species. The subtitle of Lyell’s Principles summarized the geologist’s central methodological principle: Being an Attempt to Explain the Former Changes of the Earth’s Surface, by Reference to Causes Now in Operation (emphasis in title added).8 Lyell argued that when scientists seek to explain events in the past, they should not invoke unknown or exotic causes, the effects of which we do not know. Instead, they should cite causes that are known from our uniform experience to have the power to produce the effect in question. Historical scientists should cite “causes now in operation” or presently acting causes. This was the idea behind his uniformitarian principle and the dictum, “The present is the key to the past.” According to Lyell, our present experience of cause and effect should guide our reasoning about the causes of past events. Darwin himself adopted this methodological principle as he sought to demonstrate that natural selection qualified as a vera causa, that is, a true, known, or actual cause of significant biological change.9 He sought to show that natural selection was “causally adequate” to produce the effects he was trying to explain.
Both philosophers of science and leading historical scientists have emphasized causal adequacy as the key criterion by which competing hypotheses are adjudicated. But philosophers of science also have noted that assessments of explanatory power lead to conclusive inferences only when it can be shown that there is only one known cause for the effect or evidence in question.10 When scientists can infer a uniquely plausible cause, they avoid the logical fallacy of affirming the consequent (or ignoring other possible causes with the power to produce the same effect).11
Secondly, after establishing parameters for evaluating competing explanations of the origin of the information necessary to produce the first life, I consciously employ the method of multiple competing hypotheses to make a positive case for intelligent design based upon the presence of functionally specified information in the cell. My book argues that intelligent design provides the best — “most causally adequate” — explanation of the origin of the functional or specified information necessary to produce life in the first place.
To do so, Signature in the Cell argues, first, that no purely undirected physical or chemical process — whether those based upon chance, law-like necessity, or the combination of the two — has provided an adequate causal explanation for the ultimate origin of the functionally specified biological information. In making that claim, I specifically stipulate that I am talking about undirected physical or chemical processes, not processes (such as random genetic mutation and natural selection) that commence only once life has begun. (Clearly, material processes that only commence once life has begun cannot be invoked to explain the origin of the information necessary to produce life in the first place). Nevertheless, I do examine the leading naturalistic attempts to account for the ultimate origin of biological information, including chance-based theories, self-organizational theories, theories of prebiotic natural selection, including the RNA world hypothesis and DNA-first, protein-first, and metabolism-first theories. As a result of this analysis, I show that attempts to account for the origin of specified biological information starting “from purely physical or chemical antecedents” have repeatedly failed.
On the other hand, I further argue, based upon our uniform and repeated experience, we do know of a cause — a type of cause — that has demonstrated the power to produce functionally specified information from physical or chemical constituents. That cause is intelligence, or mind, or conscious activity. As information theorist Henry Quastler observed, “The creation of information is habitually associated with conscious activity.”12 Indeed, whenever we find specified information — whether embedded in a radio signal, carved in a stone monument, etched on a magnetic disc, or produced by a genetic algorithm or ribozyme engineering experiment–and we trace it back to its source, invariably we come to a mind, not merely a material process. And, as origin-of-life research itself has helped to demonstrate, we know of no other cause capable of producing functional specified information starting, again, from a purely physical or chemical state. Thus, the discovery of functionally specified, digitally encoded information in the DNA of even the simplest living cells provides compelling positive evidence for the activity of a prior designing intelligence at the point of the origin of the first life.
Missing a Basic Distinction
To refute a best-explanation argument, Venema correctly understands that he must cite an alternative explanation with equal or superior explanatory power. That means he must show that some other process or cause (other than intelligence) has demonstrated the power to produce the effect in question. Unfortunately, throughout most of his review, Venema equivocates in his description of that effect (i.e., what needs to be explained). He fails to distinguish between the ultimate origin of the biological information necessary to produce the first life and the addition of information necessary to produce new forms of life (or new proteins) from preexisting genetic information and living organisms. Instead, he spends much of his review attempting to establish that natural selection and random genetic mutations can add new genetic information to preexisting organisms, apparently unaware that he is defending at length a claim that my book does not challenge. Thus, Venema incorrectly insists that “Meyer’s main argument” concerns “the inability of random mutation and selection to add information to DNA (p. 278, emphasis mine).”
I happen to think — but do not argue in Signature in the Cell — that there are significant grounds for doubting that mutation and selection can add enough new information to account for various macroevolutionary innovations. Nevertheless, the book that Venema was reviewing, Signature in the Cell, does not address the issue of biological evolution, nor does it challenge whether mutation and selection can add new information to DNA. That is simply not what the book is about. Instead, it argues that no undirected chemical process has demonstrated the capacity to produce the information necessary to generate life in the first place. The book addresses the subject of chemical evolution and the origin of life, not biological evolution and its subsequent diversification. To imply otherwise, as Venema does, is simply to critique a straw man.
To those unfamiliar with the particular problems faced by origin-of-life research, the distinction between prebiotic and postbiotic information generation might seem like hairsplitting. After all, it might be argued that if natural selection can generate new information in living organisms, why can it also not do so in a prebiotic environment? But the distinction between a biotic and prebiotic context is crucially important. The process of natural selection classically understood presupposes the differential reproduction of living organisms and thus a preexisting mechanism of self-replication. Yet, self-replication in all extant cells depends upon functional (and therefore, sequence-specific, information-rich) proteins and nucleic acids. Yet the origin of such information-rich molecules is precisely what origin-of-life research needs to explain. For this reason, Theodosius Dobzhansky insisted, “Pre-biological natural selection is a contradiction in terms.”13 Or as Christian de Duve has explained, theories of prebiotic natural selection fail because they “need information which implies they have to presuppose what is to be explained in the first place.” 14
Of course, some origin-of-life researchers, in particular those advocating the RNA world hypothesis, have attempted to extend the concept of natural selection and differential reproduction to nonliving molecules. In particular, some researchers have proposed that self-replicating RNA molecules might establish something akin to natural selection in a prebiotic context. Nevertheless, I critique this proposal at length in my book (see summary below). Yet Venema neither acknowledges nor refutes that critique. Instead, he conflates the problems of generating information via biological and prebiological natural selection, and in so doing, fails to grapple with the critical difficulties in origin-of-life research that partly underscore the cogency of my argument.
In addition to “refuting” claims I do not make, Venema devotes an entire section of his review to criticizing the book for failing to discuss common ancestry.15 Nevertheless, the theory of universal common descent is part of the theory of biological evolution — both classical Darwinism and the neo-Darwinian synthesis. Since Signature in the Cell does not challenge either of these two theories, there was no reason for it to address the evidence for (or against) universal common descent. Needless to say, common ancestry does not become an issue until life has arisen. And again, my book is about the origin of life, not its subsequent development.16
Relevant (but Inadequate) Critiques: Metabolism First and the RNA World
After spending most of his critique of Signature in the Cell defending a mechanism of biological evolution, Venema does at last return to evaluating the claims of the book itself, however briefly. When he does, he grudgingly acknowledges that “Meyer is correct that no complete mechanism for abiogenesis has yet been put forward.” Nevertheless, he then faults the book for
focus[ing] disproportionately on outdated, discarded origin-of-life hypotheses, giv[ing] current science on the issue short shrift … for example, the major model favored by many scientists is the “RNA world” hypothesis, yet Meyer spends little time on it. Other current models, such as “metabolism first” hypotheses, receive no attention at all. This seriously compromises Meyer’s argument, since his conclusion of design depends on his assertion that he has performed a “thorough search” to exclude all natural alternatives to intelligent intervention at the origin of life. … Of this section [critiquing naturalistic models], the only current origin-of-life model (the RNA world) merits a slim chapter of twenty-eight pages. (p. 280)
It is important when encountering such critique to keep an eye on the ball. Discerning readers will notice that Venema did not offer what would have been necessary to refute the thesis of the book, namely, a causally adequate alternative explanation for the origin of the information necessary to produce the first life. Instead, he effectively concedes the main argument of the book by acknowledging that “no such mechanism . . . has been put forward” (p. 280). He does not argue, for example, that either the RNA world hypothesis or the metabolism-first model explains either the origin of life or the origin of the information necessary to produce it. Instead, his critique merely distracts attention from the central issue of the ultimate origin of biological information by quibbling about the length of my chapters, my “lack of depth in modern origin-of-life research” (p. 280), and my “rookie errors” (p. 281)!17
But what of his specific criticisms? Does Signature in the Cell fail to make a thorough search for alternative naturalistic explanations for the origin of biological information? Does it give the RNA world hypothesis “short shrift”?
I am sorry to say that in each case it is Venema’s scholarship that is lacking. He claims that my book does not address the metabolism-first hypothesis. This is false. Signature in the Cell provides a detailed critique of the most extensively developed metabolism-first proposal, Stuart Kauffman’s theory described in his 700-page book The Origins of Order.18 Moreover, the article that Venema commends to my attention, by the late Leslie Orgel, hardly solves the problem of the origin of life or information, as Orgel explained in the article that Venema cites. As Orgel notes,
The suggestion that relatively pure, complex organic molecules might be made available in large amounts via a self-organizing, autocatalytic cycle might, in principle, help to explain the origin of the component monomers. [Yet] I have emphasized the implausibility of the suggestion that complicated cycles could self-organize.19
In his more recent 2008 paper titled “The Implausibility of Metabolic Cycles on the Prebiotic Earth,” Orgel is even more adamant:
Almost all proposals of hypothetical metabolic cycles have recognized that each of the steps involved must occur rapidly enough for the cycle to be useful in the time available for its operation. It is always assumed that this condition is met, but in no case have persuasive supporting arguments been presented. Why should one believe that an ensemble of minerals that are capable of catalyzing each of the many steps of the reverse citric acid cycle was present anywhere on the primitive Earth or that the cycle mysteriously organized itself topographically on a metal sulfide surface? The lack of a supporting background in chemistry is even more evident in proposals that metabolic cycles can evolve to “life-like” complexity. The most serious challenge to proponents of metabolic [first] cycle theories–the problems presented by the lack of specificity of most nonenzymatic catalysts — has, in general, not been appreciated. If it has, it has been ignored. Theories of the origin of life based on metabolic cycles cannot be justified by the inadequacy of competing theories: they must stand on their own.20
Venema’s citation of Orgel as a representative of the metabolism-first theory gives the misleading impression that Orgel advocated this theory and that, therefore, Signature in the Cell should have addressed it as a significant alternative explanation. But not only does Signature in the Cell address, arguably, the most well-developed metabolism-first theory (i.e., Kauffman’s), it also critiques the same fundamental flaw in metabolism-first theories that Orgel himself highlights, namely, that metabolism-first theories do not account for the information-rich enzymatic complexity necessary to establish autocatalytic metabolic cycles. Orgel does not just criticize these theories. His criticisms are similar to those found in Signature in the Cell. Why then cite Orgel against the book, as Venema does?
Venema also claims my book disproportionately focuses on outdated origin-of-life theories. Yet he fails to inform his readers that the book quite intentionally performed a chronological investigation of the major attempts that have been made to solve the problem of the origin of biological information from the 1950s until the present. Moreover, I trace the development of these ideas (a) precisely to insure that the book makes a thorough search of alternative naturalistic explanations and (b) to establish for readers the depth and severity of the problem facing naturalistic attempts to explain the origin of biological information.
Meanwhile, Venema’s critique of my discussion of the RNA world hypothesis is facile. His sole criticism of my discussion is that it encompasses “only” twenty-eight printed pages. Yet, scientific ideas are not judged by the number of words or pages required to explain (or critique) them, nor does a 10,000-word chapter including references constitute a “slim” or cursory treatment, especially since it takes far fewer words to explain the main reasons the theory fails (see below). In any case, to show that the RNA world refutes the thesis of Signature in the Cell, Venema needed to establish (or, at least, assert authoritatively) that the RNA world has solved the problem of the origin of life or the origin of biological information. To do that, he would need to rebut the arguments made in my chapter, and this he does not do. Nor can he do so. Instead, it is the RNA world hypothesis that gives short shrift to the real problems facing naturalistic accounts of abiogenesis.
Problems with the RNA World Hypothesis
As readers will recall, the RNA world was proposed as an explanation for the origin of the interdependence of nucleic acids and proteins in the cell’s information-processing system. In extant cells, building proteins requires genetic information from DNA, but information in DNA cannot be processed without many specific proteins and protein complexes. This poses a chicken-or-egg problem. The discovery that RNA (a nucleic acid) possesses some limited catalytic properties similar to those of proteins suggested a potential way to solve that problem. “RNA-first” advocates proposed an early state in which RNA performed both the enzymatic functions of modern proteins and the information-storage function of modern DNA, thus allegedly making the interdependence of DNA and proteins unnecessary in the earliest living system.21
But as I show in Signature in the Cell, there are a number of compelling reasons to doubt this hypothesis, none of which Venema addresses or refutes.
First, synthesizing (and/or maintaining) many essential building blocks of RNA molecules under realistic conditions without unrealistic levels of intelligent manipulation from investigators has proven to be extremely difficult.22
Second, ribozymes acting on their own, without the help of proteins, are known to perform only a tiny set of simple reactions. They do not perform anything like the range of functions that proteins do, and there are physical reasons for this. Proteins use a combination of hydrophilic and hydrophobic building blocks to make large, well-formed molecular structures with a wide variety of stable shapes. RNAs, which are limited to four hydrophilic bases, cannot do this. Thus, for example, true protein enzymes are capable of coupling energetically favorable and energetically unfavorable reactions together. Ribozymes are not.
Third, RNA-world advocates offer no plausible explanation for how primitive RNA replicators might have evolved into modern cells that rely heavily on proteins to process and translate genetic information and regulate metabolism.23
Fourth, attempts to enhance the limited catalytic properties of RNA molecules in so-called ribozyme engineering experiments have inevitably required extensive investigator manipulation, thus demonstrating, if anything, the need for intelligent design, not the efficacy of an undirected chemical evolutionary process.
Most importantly for our present considerations, the RNA-world hypothesis presupposes, but does not explain, the origin of sequence specificity or information in the original (hypothetical) self-replicating RNA molecules.24 To date, scientists have been able to design RNA catalysts that will copy only about 10% of themselves.25 For strands of RNA to perform even this limited replicase (self-replication) function, however, they must, like proteins, have very specific arrangements of constituent building blocks (nucleotides, in the RNA case). Further, the strands must be long enough to fold into complex three-dimensional shapes (to form so-called tertiary structures). Thus, any RNA molecule capable of even limited function must have possessed considerable (specified) information content. Yet, explaining how the building blocks of RNA arranged themselves into functionally specified sequences has proven no easier than explaining how the constituent parts of DNA might have done so, especially given the high probability of destructive cross-reactions between desirable and undesirable molecules in any realistic prebiotic soup. As de Duve has noted in a critique of the RNA-world hypothesis, “Hitching the components together in the right manner raises additional problems of such magnitude that no one has yet attempted to [solve them] in a prebiotic context.”26
Unless Venema can show that this problem has been solved in a prebiotic context, he has no grounds for dismissing my chapters as “too short.” My chapter was more than long enough to expose this and several other major (and widely acknowledged) deficiencies in the RNA world model.
Direct Template Models of the Origin of the Genetic Code
Venema offers one additional critique of Signature in the Cell that seems, at least, to have tangential relevance to the main argument of the book. Venema claims that Signature in the Cell was remiss in not discussing some recent “direct templating models” of the origin of the genetic code. He cites a paper published (as it happens, after the publication of Signature in the Cell)27 by Michael Yarus and colleagues at the University of Colorado. The paper purports to show that the origin of the genetic code can be explained as the result of stereochemical affinities between RNA triplets and the corresponding (cognate) amino acids with which they are associated in the genetic code.28
Yarus and his co-researchers looked for RNA strands that bound certain amino acids preferentially, from a class of RNA molecules now dubbed “aptamers.” Further, Yarus himself has asserted that his work undermines a key claim of the theory of intelligent design, because he thinks that it shows that specified complexity can arise by purely natural processes.29 Moreover, Yarus et al. have assembled a significant body of novel experimental data, which they argue support their hypothesis.30
Yarus’s work does address an important aspect of the origin-of-life problem. Nevertheless, even if its narrower empirical claims about the existence of a stereochemical basis for the genetic code are correct (and there are strong reasons to doubt this, see below), it does not follow that Yarus’s work refutes the argument of Signature in the Cell. My book argues that organisms were intelligently designed, mainly because of the presence, in their DNA and RNA, of what might be called genetic text (i.e., genes) —sequences of specifically arranged nucleotide bases that provide instructions for building proteins. Signature in the Cell addresses what in origin-of-life research is known as the sequencing problem, and presents intelligent design as the solution to it.
Yarus’s experimental work does not solve the sequencing problem, although he seems to think (incorrectly) that his work may solve it indirectly. Yarus et al. want to demonstrate that particular RNA triplets show chemical affinities to particular amino acids (their cognates in the present-day code). They do this by showing that in some RNA strands, individual triplets and their cognate amino acids bind preferentially to each other. Further, since they think that stereochemical affinities originally caused protein synthesis to occur by direct templating, they seem to think that solving the problem of the origin of the code would also simultaneously solve the problem of sequencing.
But this does not follow. Even if we assume that Yarus and his colleagues had succeeded in establishing a stereochemical basis for the associations between RNA triplets and amino acids in the present-day code (a dubious proposition, see below31), Yarus would not have solved the problem of sequencing. Why? Yarus did not find RNA strands with a properly sequenced series of triplets, each forming an association with a code-relevant amino acid. Instead, he and his fellow researchers analyzed RNA strands enriched in specific code-relevant triplets. They claim to have found that these strands show a chemical affinity to bind individual code-relevant cognate amino acids. But to synthesize proteins by direct templating (even assuming the existence of all necessary affinities), the RNA template must have many properly sequenced triplets, just as we find in the actual messenger RNA transcripts.
To produce such transcripts, however, would require excising the functional (information-carrying) triplets, with code-relevant affinities, from the otherwise nonfunctional, noncode-relevant sections of RNA present in the “aptamers” in which Yarus claims to have found code-relevant affinities. Further, once excised, these functional code-relevant triplets would have to be concatenated and arranged, to construct something akin to a gene that could directly template functional proteins (see fig. 1). But Yarus et al. do not explain how any of this, least of all the specific arrangement of the triplets, would occur. Thus they fail to solve, or even address, the sequencing problem.
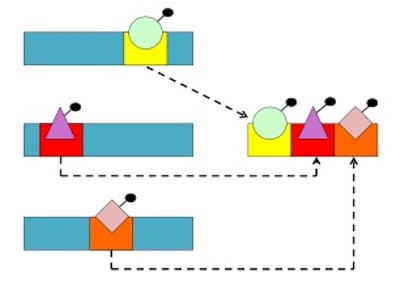 Figure 1. The sequencing problem. RNA nucleotides which bind amino acids (e.g., as represented by the green circle or purple triangle) occur in aptamers with nonbinding bases. Thus, to specify protein sequences, which require many different amino acids, code-relevant (i.e., amino acid-binding) nucleotides must be removed from their native aptamers and re-assembled into new, much longer aptamers with correct orientations and molecular distances, to achieve functional sequences of binding sites. |
Instead, Yarus attempts to explain the origin of the genetic code–or more precisely, one aspect of the translation system, the origin of the associations between certain RNA triplets and their cognate amino acids — without explaining the origin of the sequence-specific genetic text. Thus, even if Yarus and his colleagues had succeeded in explaining the origin of these associations (which they do not, see below), and even if these associations constituted a fully functional code (itself a questionable proposition, see below), their work would leave unaddressed the crucial sequencing problem and the main information argument for intelligent design presented in Signature in the Cell.32
Since Yarus’s model does not solve, nor in reality address, the central information problem discussed in Signature in the Cell, the book did not address it. Nevertheless, I have, with Paul Nelson, performed a thorough critique of Yarus’s work in a forthcoming technical article. In addition to showing that Yarus does not (really) attempt to solve the sequencing problem, we also show that
- Yarus’s methods of selecting amino-acid-binding RNA sequences ignored aptamers that did not contain the sought-after codons or anti-codons, biasing their statistical model in favor of the desired results;
- The reported results exhibited a 79% failure rate, casting doubt on the legitimacy of the “correct” results;
- Yarus et al. then simply assumed a naturalistic chemical origin for various complex biochemicals, even though there is no evidence at present for such abiotic pathways;
- Recognizing the possibility that the RNA aptamers will introduce steric hindrance to peptide bond formation, Yarus et al. carefully engineer their aptamers. In short, they inadvertently and ironically simulate the need for intelligent design to make their proposal plausible.
In summary, our article shows that Yarus neither establishes a stereochemical basis for the genetic code nor explains the origin of the sequence-specific “genetic text” found in DNA and RNA.
Conclusion
I appreciate the opportunity to address the issues raised in Dennis Venema’s review. Yet, clearly, Venema did not refute the argument of Signature in the Cell. The origin-of-life scenarios that Venema cites as alternatives to intelligent design lack biochemical plausibility and do not account for the ultimate origin of biological information. Moreover, Venema failed to recognize the importance of an elementary distinction between chemical and biological evolution in his assessment of my thesis. In this regard, his review followed a curious, but all-too-familiar pattern. Since he is unable to point to any chemical evolutionary mechanism that can account for the ultimate origin of information, Venema — like other critics of Signature in the Cell such as Darrel Falk and Francisco Ayala — attempts to demonstrate with various examples that the neo-Darwinian mechanism can generate (at least) some new information — albeit in each case starting from a preexisting organism. And so, he spends the balance of his review rebutting a book on biological evolution that I did not write.
Even so, readers should beware of his confident assertions about the alleged creative power of natural selection and random mutation as a mechanism of biological evolution. He claims (following Falk and various ASA bloggers), for example, that the immune system demonstrates the power of the neo-Darwinian mechanism to produce novel genetic information. Yet recently, immunologist Donald Ewert has shown that (a) the immune system produces only a limited amount of new biological information (and clearly not enough information, or the right kind of information, to accomplish major evolutionary transformations) and (b) that the immune system in no way models the random and undirected neo-Darwinian process of mutation and selection. Instead, it is preprogrammed to allow only certain types of mutations within certain portions of certain genes, and it uses a carefully controlled and regulated goal directed process of selection.33 In a similar vein, protein engineer Doug Axe has decisively rebutted Arthur Hunt’s critique of Axe’s work,34which Venema recycled uncritically in his review of my book.
In any case, Venema’s review of Signature in the Cell is compromised by his misrepresentation of the thesis of the book, by his citation of sources that do not support his critique, and by a superficial discussion of alternative theories of the origin of life. Though I appreciate his intended evidential approach, the execution of his analysis leaves much to be desired. Accordingly, I encourage PSCF readers to consider the merits of Signature in the Cell for themselves.
References Cited
- See D. R. Venema, “Seeking a Signature,” Perspectives on Science and Christian Faith 62, no. 4 (2010): 276-83.
- Bernd-Olaf Küppers, Information and the Origin of Life (Cambridge, MA: MIT Press, 1990), 170-72.
- See J. W. Szostak, “Molecular Messages,” Nature 423 (2003): 689; R. M. Hazen, P. L. Griffin, J. M. Carothers, and J. W. Szostak, “Functional Information and the Emergence of Biocomplexity,” Proceedings of the National Academy of Sciences USA 104 (2007): 8574-81.
- L. E. Orgel, The Origins of Life: Molecules and Natural Selection (City, ST: Chapman & Hall, 1973): 189.
- T. C. Chamberlin, “The Method of Multiple Working Hypotheses,” Science 15 (1890): 92-96; reprinted in Science 148 (1965): 754-59.
- P. Lipton, Inference to the Best Explanation (New York: Routledge, 1991): 1, 32-88.
- Ibid.
- C. Lyell, Principles of Geology: Being an Attempt to Explain the Former Changes of the Earth’s Surface, by Reference to Causes Now in Operation, vol. 1 (London: John Murray, 1830-1833), 75-91.
- V. Kavalovski, The Vera Causa Principle: A Historico-Philosophical Study of a Meta-Theoretical Concept from Newton through Darwin (Ph.D. diss., University of Chicago, 1974), 78-103.
- M. Scriven, “Explanation and Prediction in Evolutionary Theory,” Science 130 (1959): 477-82.
- S. Meyer, Clues and Causes: A Methodological Interpretation of Origin of Life Studies (Ph.D. diss., Cambridge University, 1990), 96-108.
- H. Quastler, The Emergence of Biological Organization (New Haven, CT: Yale University Press 1964), 16.
- T. Dobzhansky, “Discussion of G. Schramm’s Paper,” in S. W. Fox, ed., The Origins of Prebiological Systems and of Their Molecular Matrices (New York: Academic Press, 1965), 310.
- (14) C. de Duve, Blueprint for a Cell: The Nature and Origin of Life (Burlington, NC: Neil Patterson Publishers, 1991), 187.
- As Venema writes in part, “Meyer does not tackle this evidence or, for that matter, any evidence relevant to common ancestry” (p. 278).
- In fairness to Dennis, I do have an idea about how the confusion might have arisen in his mind. I do discuss in an appendix Doug Axe’s work establishing the extreme rarity (and thus isolation, see below) of functional proteins within the vast space of possible amino acid combinations corresponding to proteins of even modest length. And it is true that Axe regards this rarity (and isolation) as a severe challenge to the efficacy of selection and mutation as a mechanism for generating new genes and proteins (and, thus, information) in a biological context. Further, Axe also favors intelligent design as an alternative to neo-Darwinian biological evolution in part for this reason.
Nevertheless, I discussed Axe’s work to illustrate how various ID hypotheses can generate testable predictions in response to the objection that intelligent design doesn’t generate testable predictions. I did not cite Axe’s work as part of a critique of the neo-Darwinian mechanism (however much I may, or may not, doubt it). My argument for intelligent design as an alternative to chemical evolutionary theory conceded (at least, ad arguendo) the efficacy of that mechanism. I cited Axe, instead, to answer the oft-stated objection that design hypotheses are not scientific because they make no testable predictions.
Perhaps, if Dennis reads the book more carefully, he will concede that he took my discussion of Axe’s work out of context and built the balance of his critique of the book atop that misunderstanding. (By the way, in that same appendix, I also discussed various predictions that follow from front-end-loaded conceptions of intelligent design that assume the adequacy of neo-Darwinism. Obviously, if I had meant my appendix to function as a critique of neo-Darwinism, I would not have highlighted predictions that flow from ID hypotheses which assume the truth of that theory.) - Venema catches a factual error in the book for which I am grateful. He notes that I should not have referred to ribosomes as “protein dominated.” Heis right. Ribosomes have more RNA than protein by weight (by about a 3 to 2 ratio in eukaryotes and a 2 to 1 ratio in prokaryotes). Also, RNA in the ribosome performs a necessary (though not sufficient) functional role in peptide bond formation. So the phrase “protein dominated” was ill-chosen.
Nevertheless, Venema then attempts to make a rhetorical mountain out of this factual molehill in an attempt to refute one of my critiques of the RNA world hypothesis. He argues that “Meyer claims that modern ribosomes are ‘protein dominated’ and [falsely] presents this as a hurdle for the RNA world to explain” (p. 280). According to Venema, my error undermines my critique of RNA world because it overlooks that “the modern [ribosome] system uses an RNA enzyme for protein synthesis . . .” (p. 280).
But Venema misunderstands my argument and misrepresents me. First, I repeatedly note that ribosomes need both proteins and RNAs to accomplish peptide bond formation at the ribosome site (p. 304-309). Second, I do not argue that the absence of RNA or the dominance of proteins in the ribosome represents a “hurdle for the RNA world to explain.” I argue that the (mere) presence of proteins in the translation system (both in the ribosome and elsewhere) challenges the RNA world hypothesis.
Here is why: As I explain in Signature “to evolve beyond the RNA World, an RNA-based replication system would eventually have to begin to produce proteins” (p. 305). But “in modern cells it takes many proteins to build proteins. So, as a first step toward building proteins, the primitive RNA replicator would need to produce RNA molecules capable of performing the functions of the modern proteins involved in translation.”
Yet, as I show, RNA molecules cannot perform many of the crucial functions that proteins (and protein enzymes) can perform, including many of the functions that proteins perform in the translation process. Moreover, there are physical reasons for this. Proteins use a combination of hydrophilic and hydrophobic building blocks to make large, well-formed molecular structures with a wide variety of stable shapes, whereas RNAs, which are limited to four hydrophilic bases, cannot do this.
For example, as a result of their greater structural stability and complexity, protein enzymes can couple energetically favorable and unfavorable reactions together into a series of reactions that are energetically favorable overall. As a result, they can drive forward two reactions where ordinarily only one would occur with any appreciable frequency. RNA catalysts cannot do this. Yet such coordinated and coupled reactions are critical to many aspects of the translation process, including the reactions catalyzed by the crucial tRNA synthetases.
Because of the need for such coupled reactions and the functional limitations associated with RNA catalysts, the RNA world hypothesis offers no credible account of the origin of a protein-based, or even a partially protein-based, translation system from an earlier exclusively RNA-based replication system.
Venema does not accurately represent this criticism of the RNA world, let alone answer it. Instead, he glosses over the problem of explaining the origin of proteins (or ribozymes with specific protein-like functions). As such, his review trivializes my concerns about the plausibility of the RNA world hypothesis by obscuring its real difficulties. Once again, Venema attacks. . .the straw man. - S. A. Kauffman, The Origins of Order: Self-Organization and Selection in Evolution (New York: Oxford University Press, Inc., 1993): 285-341.
- L. E. Orgel, “Self-organizing biochemical cycles,” Proceedings of the National Academy of Sciences USA 97 (2000): 12503-7 (emphasis added).
- L. E. Orgel, “The Implausibility of Metabolic Cycles on the Prebiotic Earth,” PLoS Biology 6 (2008): 5-13 (emphasis added to highlight a critique of Kauffman’s model made in Signature).
- For example, see J. W. Szostak, D. P. Bartel, and P. L. Luisi, “Synthesizing life,” Nature 409 (2001): 387-90; G. F. Joyce, “The antiquity of RNA-based evolution,” Nature, 418 (2002): 214-21.
- R. Shapiro, “Prebiotic Cytosine Synthesis: A Critical Analysis and Implications for the Origin of Life,” Proceedings of the National Academy of Sciences, USA 96 (1999): 4396-4401; M. W. Powner, B. Gerland, and J. D. Sutherland, “Synthesis of Activated Pyrimidine Ribonucleotides in Prebiotically Plausible Conditions,” Nature 459 (2009): 239-42. For a response to Powner et al. (2009), see comments by Robert Shapiro in James Urquhart, “Insights into RNA Origins,” Chemistry World, Royal Society of Chemistry (2009). See here (last accessed April 3, 2011).
Some critics of my book have attempted to dispute this claim. Darrel Falk, for example, first cites a scientific study published last spring after my book was in press. The paper authored by University of Manchester chemist John Sutherland and two colleagues, does partially address one of the many outstanding difficulties associated with the RNA world, the most popular current theory about the origin of the first life. Starting with a 3-carbon sugar (D-glyceraldehyde), and another molecule called 2-aminooxazole, Sutherland successfully synthesized a 5-carbon sugar in association with a base and a phosphate group. In other words, he produced a ribonucleotide. The scientific press justifiably heralded this as a breakthrough in prebiotic chemistry because previously chemists had thought (as I noted in my book) that the conditions under which ribose and bases could be synthesized were starkly incompatible with each other.
Even so, Sutherland’s work lacks prebiotic plausibility and does so in three ways. First, Sutherland chose to begin his reaction with only the right-handed isomer of the 3-carbon sugars he needed to initiate his reaction sequence. Why? Because he knew that otherwise the likely result would have had little biological significance. Had Sutherland chosen to use a far more plausible racemic mixture of both right- and left-handed sugar isomers, his reaction would have generated undesirable mixtures of stereoisomers–mixtures that would seriously complicate any subsequent biologically relevant polymerization. Thus, he himself solved the so-called chirality problem in origin-of-life chemistry by intelligently selecting a single enantiomer, i.e., only the right-handed sugars that life itself requires. Yet there is no demonstrated source for such nonracemic mixture of sugars in any plausible prebiotic environment.
Second, the reaction that Sutherland used to produce ribonucleotides involved numerous separate chemical steps. At each intermediate stage in his multistep reaction sequence, Sutherland himself intervened to purify the chemical by-products of the previous step by removing undesirable side products. In so doing, he prevented — by his own will, intellect and experimental technique — the occurrence of interfering cross-reactions, the scourge of the prebiotic chemist.
Third, in order to produce the desired chemical product — ribonucleotides — Sutherland followed a very precise “recipe” or procedure in which he carefully selected the reagents and choreographed the order in which they were introduced into the reaction series, just as he also selected which side products to be removed and when. Such recipes, and the actions of chemists who follow them, represent what the late Hungarian physical chemist Michael Polanyi called “profoundly informative intervention[s].” Information is being added to the chemical system as the result of the deliberative actions — the intelligent design — of the chemist himself. - Y. I. Wolf and E. V. Koonin, “On the Origin of the Translation System and the Genetic Code in the RNA World by Means of Natural Selection, Exaptation, and Subfunctionalization,” Biology Direct 2 (2007): 14.
- Some reviewers, such as Darrel Falk and Stephen Fletcher, have also attempted to refute my critique of the RNA world by citing the recent paper by Tracey Lincoln and Gerald Joyce ostensibly establishing the capacity of RNA to self-replicate, thereby rendering plausible one of the key steps in the RNA world hypothesis. Falk incorrectly intimates that I did not discuss this experiment in my book. In fact, I do discuss it on page 537 of Signature in the Cell.
In any case, Falk and Fletcher draw exactly the wrong conclusion from this paper. The central problem facing origin-of-life researchers is neither the synthesis of prebiotic building blocks or even the synthesis of a self-replicating RNA molecule (the plausibility of which Joyce and Tracey’s work seeks to establish, albeit unsuccessfully, see below). Instead, the fundamental problem is getting the chemical building blocks to arrange themselves into the large information-bearing molecules (whether DNA or RNA). As I show in Signature in the Cell, even the extremely limited capacity for RNA self-replication that has been demonstrated depends critically on the specificity of the arrangement of nucleotide bases–that is, upon preexisting sequence-specific information.
The Lincoln and Joyce experiment does not solve this problem, at least not apart from the intelligence of Lincoln and Joyce. In the first place, the “self-replicating” RNA molecules that they construct are not capable of copying a template of genetic information from free-standing chemical subunits as the polymerase machinery does in actual cells. Instead, in Lincoln and Joyce’s experiment, a presynthesized specifically sequenced RNA molecule merely catalyzes the formation of a single chemical bond, thus fusing two other presynthesized partial RNA chains. In other words, their version of “self-replication” amounts to nothing more than joining two sequence-specific premade halves together. More significantly, Lincoln and Joyce themselves intelligently arranged the matching base sequences in these RNA chains. They did the work of replication. They generated the functionally specific information that made even this limited form of replication possible.
The Lincoln and Joyce experiment actually confirms three related claims that I make in Signature in the Cell. First, it demonstrates that even the capacity for modest partial self-replication in RNA itself depends upon sequence specific (i.e., information-rich) base sequences in these molecules.
Second, it shows that even the capacity for partial replication of genetic information in RNA molecules results from the activity of chemists, that is, from the intelligence of the “ribozyme engineers” who design and select the features of these (partial) RNA replicators.
Third, prebiotic simulation experiments themselves confirm what we know from ordinary experience, namely, that intelligent design is the only known means by which functionally specified information arises.
See S. Fletcher, TLS Letters 03/02/10. The Sunday Times (2010). See here (last accessed April 1, 2011). D. Falk, “Signature in the Cell” (2009). See here (last accessed April 1, 2011). T. A. Lincoln and G. F. Joyce, “Self-Sustained Replication of an RNA Enzyme,” Science 323 (2009):1229-32. See also responses to Fletcher and Falk at S. Meyer, “Stephen Meyer Responds to Stephen Fletcher’s Attack Letter in the Times Literary Supplement.” See here (last accessed April 1, 2011). S. Meyer, “Response to Darrel Falk’s Review of Signature in the Cell.” See here (last accessed April 1, 2011). - W. K. Johnston, P. J. Unrau, M. S. Lawrence, M. E. Glasner and D. P. Bartel, “RNA-Catalyzed RNA Polymerization: Accurate and General RNA-Templated Primer Extension,” Science 292 (2001): 1319-25.
- C. de Duve, Vital Dust: Life as a Cosmic Imperative (New York: Basic Books, 1995), 23.
- Signature in the Cell was published in June 2009, with the manuscript obviously having been completed months prior. Yarus’s paper was not published until October 2009.
- Specifically, Venema cites M. Yarus, J. Widmann, and R. Knight, “RNA-Amino Acid Binding: A Stereochemical Era for the Genetic Code,” Journal of Molecular Evolution 69 (2009): 406-29.
- M. Yarus, Life from An RNA World: The Ancestor Within (Cambridge, MA: Harvard University Press, 2009).
- See M. Yarus M, “A specific amino acid binding site composed of RNA,” Science 240 (1988): 1751-8; M. Yarus M and E. L. Christian “Genetic Code Origins,” Nature 342 (1989): 349-50; I. Majerfeld and M. Yarus, “An RNA Pocket for an Aliphatic Hydrophobe,” Nature Structural Biology 1 (1994): 287-92; I. Majerfeld and M. Yarus, “A Diminutive and Specific RNA Binding Site for L-Tryptophan,” Nucleic Acids Research 33 (2005): 5482-93; M. Yarus, J. Widmann, and R. Knight, “RNA-Amino Acid Binding: A Stereochemical Era for the Genetic Code,” Journal of Molecular Evolution 69 (2009): 406-29.
- See S. Meyer and P. Nelson, “Can the Origin of the Genetic Code Be Explained by Direct RNA Templating? A Critical Review,” BIO-Complexity (forthcoming, July 2011).
- That said, Signature does ague that the current genetic code (as well as the text itself) defies explanation by reference to stereochemical affinities. Signature also asserts that this fact renders self-organizational explanations for the origin of the genetic code problematic. Thus, the claim byYarus et al. to have explained the origin of the code by reference to stereochemical affinities alone, does challenge one important scientific claim of Signature (although not its main argument). Nevertheless, even here, Nelson and I show in BIO-Complexity (“Can the Origin of the Genetic Code Be Explained by Direct RNA Templating? A Critical Review,” July 2011) that Yarus’s direct templating model does not succeed on its own terms.
- See D. L. Ewert, “Adaptive Immunity: Chance or Necessity?” (2010), here (last accessed April 1, 2011).
- See D. Axe, “The Rarity and Isolation of Functional Proteins in Combinatorial Sequence Space: Response to Hunt,” here (last accessed April 1, 2011).