
1. Introduction
In the preceding essay, mathematician and probability theorist William Dembski notes that human beings often detect the prior activity of rational agents in the effects they leave behind.1 Archaeologists assume, for example, that rational agents produced the inscriptions on the Rosetta Stone; insurance fraud investigators detect certain “cheating patterns” that suggest intentional manipulation of circumstances rather than “natural” disasters; and cryptographers distinguish between random signals and those that carry encoded messages.
More importantly, Dembski’s work establishes the criteria by which we can recognize the effects of rational agents and distinguish them from the effects of natural causes. In brief, he shows that systems or sequences that are both “highly complex” (or very improbable) and “specified” are always produced by intelligent agents rather than by chance and/or physicalchemical laws. Complex sequences exhibit an irregular and improbable arrangement that defies expression by a simple formula or algorithm. A specification, on the other hand, is a match or correspondence between an event or object and an independently given pattern or set of functional requirements.
As an illustration of the concepts of complexity and specification, consider the following three sets of symbols:
“inetehnsdysk]idmhcpew,ms.s/a”
“Time and tide wait for no man.”
“ABABABABABABABABABAB”
Both the first and second sequences shown above are complex because both defy reduction to a simple rule. Each represents a highly irregular, aperiodic, and improbable sequence of symbols. The third sequence is not complex but is instead highly ordered and repetitive. Of the two complex sequences, only the second exemplifies a set of independent functional requirements — that is, only the second sequence is specified. English has a number of functional requirements. For example, to convey meaning in English one must employ existing conventions of vocabulary (associations of symbol sequences with particular objects, concepts, or ideas), syntax, and grammar (such as “every sentence requires a subject and a verb”). When arrangements of symbols “match” or utilize existing vocabulary and grammatical conventions (that is, functional requirements) communication can occur. Such arrangements exhibit “specification”. The second sequence (“Time and tide wait for no man”) clearly exhibits such a match between itself and the preexisting requirements of English vocabulary and grammar.
Thus, of the three sequences above only the second manifests complexity and specification, both of which must be present for us to infer a designed system according to Dembski’s theory. The third sequence lacks complexity, though it does exhibit a simple pattern, a specification of sorts. The first sequence is complex but not specified, as we have seen. Only the second sequence, therefore, exhibits both complexity and specification. Thus, according to Dembski’s theory, only the second sequence indicates an intelligent cause — as indeed our intuition tells us.
As the above illustration suggests, Dembski’s criteria of specification and complexity bear a close relationship to certain concepts of information. As it turns out, the joint criteria of complexity and specification (or “specified complexity”) are equivalent or “isomorphic” with the term “information content”,2 as it is often used.3 Thus, Dembski’s work suggests that “high information content” indicates the activity of an intelligent agent. Common, as well as scientific, experience confirms this theoretical insight. For example, few rational people would attribute hieroglyphic inscriptions to natural forces such as wind or erosion rather than to intelligent activity.
Dembski’s work also shows how we use a comparative reasoning process to decide between natural and intelligent causes. We usually seek to explain events by reference to one of three competing types of explanation: chance, necessity (as the result of physical-chemical laws), and/or design, (that is, as the work of an intelligent agent). Dembski has created a formal model of evaluation that he calls “the explanatory filter”. The filter shows that the best explanation of an event is determined by its probabilistic features or “signature”. Chance best explains events of small or intermediate probability; necessity (or physical-chemical law) best explains events of high probability; and intelligent design best explains small probability events that also manifest specificity (of function, for example). His “explanatory filter” constitutes, in effect, a scientific method for detecting the activity of intelligence. When events are both highly improbable and specified (by an independent pattern) we can reliably detect the activity of intelligent agents. In such cases, explanations involving design are better than those that rely exclusively on chance and/or deterministic natural processes.
Dembski’s work shows that detecting the activity of intelligent agency (“inferring design”) represents an indisputably common form of rational activity. His work also suggests that the properties of complexity and specification reliably indicate the prior activity of an intelligent cause. This essay will build on this insight to address another question. It will ask: Are the criteria that indicate intelligent design present in features of nature that clearly preexist the advent of humans on earth? Are the features that indicate the activity of a designing intel-ligence present in the physical structure of the universe or in the features of living organisms? If so, does intelligent design still constitute the best explanation of these features, or might naturalistic explanations based upon chance and/or physicochemical necessity constitute a better explanation? This paper will evaluate the merits of the design argument in light of developments in physics and biology as well as Dembski’s work on “the design inference”. I will employ Dembski’s comparative explanatory method (the “explanatory filter”) to evaluate the competing explanatory power of chance, necessity, and design with respect to evidence in physics and biology. I will argue that intelligent design (rather than chance, necessity, or a combination of the two) constitutes the best explanation of these phenomena. I will, thus, suggest an empirical, as well as a theoretical, basis for resuscitating the design argument
tial conditions of the universe, and many other of its features appear delicately balanced to allow for the possibility of life. Even very slight alterations in the values of many factors, such as the expansion rate of the universe, the strength of gravitational or electromagnetic attraction, or the value of Planck’s constant, would render life impossible. Physicists now refer to these factors as “anthropic coincidences” (because they make life possible for man) and to the fortunate convergence of all these coincidences as the “fine tuning of the universe”. Given the improbability of the precise ensemble of values represented by these constants, and their specificity relative to the requirements of a life-sustaining universe, many physicists have noted that the fine tuning strongly suggests design by a preexistent intelligence. As well-known British physicist Paul Davies has put it, “the impression of design is overwhelming.”5
2.1 Evidence of Design in Physics: Anthropic “Fine Tuning”
Despite the long popularity of the design argument in the history of Western thought, most scientists and philosophers had come to reject the design argument by the beginning of the twentieth century. Developments in philosophy during the eighteenth century and developments in science during the nineteenth (such as Laplace’s nebular hypothesis and Darwin’s theory of evolution by natural selection) left most scientists and scholars convinced that nature did not manifest unequivocal evidence of intelligent design.
During the last forty years, however, developments in physics and cosmology have placed the word “design” back in the scientific vocabulary. Beginning in the 1960s, physicists unveiled a universe apparently fine-tuned for the possibility of human life. They discovered that the existence of life in the universe depends upon a highly improbable but precise balance of physical factors.4 The constants of physics, the ini-
To see why, consider the following illustration. Imagine that you are a cosmic explorer who has just stumbled into the control room of the whole universe. There you discover an elaborate “universe-creating machine”, with rows and rows of dials, each with many possible settings. As you investigate, you learn that each dial represents some particular parameter that has to be calibrated with a precise value in order to create a universe in which life can exist. One dial represents the possible settings for the strong nuclear force, one for the gravitational constant, one for Planck’s constant, one for the ratio of the neutron mass to the proton mass, one for the strength of electromagnetic attraction, and so on. As you, the cosmic explorer, examine the dials, you find that they could easily have been tuned to different settings. Moreover, you determine by careful calculation that if any of the dial settings were even slightly altered, life would cease to exist. Yet for some reason each dial is set at just the exact value necessary to keep the universe running. What do you infer about the origin of these finely tuned dial settings?
Not surprisingly, physicists have been asking the same question. As astronomer George Greenstein mused, “the thought insistently arises that some supernatural agency, or rather Agency, must be involved. Is it possible that suddenly, without intending to, we have stumbled upon scientific proof for the existence of a Supreme Being? Was it God who stepped in and so providentially crafted the cosmos for our benefit?”6 For many scientists,7 the design hypothesis seems the most obvious and intuitively plausible answer to this question. As Sir Fred Hoyle commented, “a commonsense interpretation of the facts suggests that a superintellect has monkeyed with physics, as well as chemistry and biology, and that there are no blind forces worth speaking about in nature.”8 Many physicists now concur. They would argue that, given the improbability and yet the precision of the dial settings, design seems the most plausible explanation for the anthropic fine tuning. Indeed, it is precisely the combination of the improbability (or complexity) of the settings and their specificity relative to the conditions required for a life-sustaining universe that seems to trigger the “commonsense” recognition of design.
2.2 Anthropic Fine Tuning and the Explanatory Filter
Yet several other types of interpretations have been proposed: (1) the so-called weak anthropic principle, which denies that the fine tuning needs explanation; (2) explanations based upon natural law; and (3) explanations based upon chance. Each of these approaches denies that the fine tuning of the universe resulted from an intelligent agent. Using Dembski’s “explanatory filter”, this section will compare the explanatory power of competing types of explanations for the origin of the anthropic fine tuning. It will also argue, contra (1), that the fine tuning does require explanation.
Of the three options above, perhaps the most popular approach, at least initially, was the “weak anthropic principle” (WAP). Nevertheless, the WAP has recently encountered severe criticism from philosophers of physics and cosmology. Advocates of WAP claimed that if the universe were not finetuned to allow for life, then humans would not be here to observe it. Thus, they claimed, the fine tuning requires no explanation. Yet as John Leslie and William Craig have argued, the origin of the fine tuning does require explanation.9 Though we humans should not be surprised to find ourselves living in a universe suited for life (by definition), we ought to be surprised to learn that the conditions necessary for life are so vastly improbable. Leslie likens our situation to that of a blindfolded man who has discovered that, against all odds, he has survived a firing squad of one hundred expert marksmen.10 Though his continued existence is certainly consistent with all the marksmen having missed, it does not explain why the marksmen actually did miss. In essence, the weak anthropic principle wrongly asserts that the statement of a necessary condition of an event eliminates the need for a causal explanation of that event. Oxygen is a necessary condition of fire, but saying so does not provide a causal explanation of the San Francisco fire. Similarly, the fine tuning of the physical constants of the universe is a necessary condition for the existence of life, but that does not explain, or eliminate the need to explain, the origin of the fine tuning.
While some scientists have denied that the fine-tuning coincidences require explanation (with the WAP), others have tried to find various naturalistic explanations for them. Of these, appeals to natural law have proven the least popular for a simple reason. The precise “dial settings” of the different constants of physics are specific features of the laws of nature themselves. For example, the gravitational constant G determines just how strong gravity will be, given two bodies of known mass separated by a known distance. The constant G is a term within the equation that describes gravitational attraction. In this same way, all the constants of the fundamental laws of physics are features of the laws themselves. Therefore, the laws cannot explain these features; they comprise the features that we need to explain.
As Davies has observed, the laws of physics “seem themselves to be the product of exceedingly ingenious design”.11 Further, natural laws by definition describe phenomena that conform to regular or repetitive patterns. Yet the idiosyncratic values of the physical constants and initial conditions of the universe constitute a highly irregular and nonrepetitive ensemble. It seems unlikely, therefore, that any law could explain why all the fundamental constants have exactly the values they do — why, for example, the gravitational constant should have exactly the value 6.67 × 10–11 Newton-meters2 per kilogram2 and the permittivity constant in Coulombs law the value 8.85 ×10–12 Coulombs2 per Newton-meter2, and the electron charge to mass ratio 1.76 × 1011 Coulombs per kilogram, and Planck’s constant 6.63 × 10–34 Joules-seconds, and so on.12 These values specify a highly complex array. As a group, they do not seem to exhibit a regular pattern that could in principle be subsumed or explained by natural law.
Explaining anthropic coincidences as the product of chance has proven more popular, but this has several severe liabilities as well. First, the immense improbability of the fine tuning makes straightforward appeals to chance untenable. Physicists have discovered more than thirty separate physical or cosmological parameters that require precise calibration in order to produce a life-sustaining universe.13 Michael Denton, in his book Nature’s Destiny (1998), has documented many other necessary conditions for specifically human life from chemistry, geology, and biology. Moreover, many individual parameters exhibit an extraordinarily high degree of fine tuning. The expansion rate of the universe must be calibrated to one part in1060.14 A slightly more rapid rate of expansion — by one part in 1060 — would have resulted in a universe too diffuse in matter to allow stellar formation.15 An even slightly less rapid rate of expansion — by the same factor — would have produced an immediate gravitational recollapse. The force of gravity itself requires fine tuning to one part in 1040.16 Thus, our cosmic explorer finds himself confronted not only with a large ensemble of separate dial settings but with very large dials containing a vast array of possible settings, only very few of which allow for a life-sustaining universe. In many cases, the odds of arriving at a single correct setting by chance, let alone all the correct settings, turn out to be virtually infinitesimal. Oxford physicist Roger Penrose has noted that a single parameter, the so-called “original phase-space volume”, required such precise fine tuning that the “Creator’s aim must have been [precise] to an accuracy of one part in 1010123” (which is ten billion multiplied by itself 123 times). Penrose goes on to remark that, “one could not possibly even write the number down in full … [since] it would be ‘1’ followed by 10123 successive ‘0’s!” — more zeros than the number of elementary particles in the entire universe. Such is, he concludes, “the precision needed to set the universe on its course”.17
To circumvent such vast improbabilities, some scientists have postulated the existence of a quasi-infinite number of parallel universes. By doing so, they increase the amount of time and number of possible trials available to generate a life-sustaining universe and thus increase the probability of such a universe arising by chance. In these “many worlds” or “possible worlds” scenarios — which were originally developed as part of the “Everett interpretation” of quantum physics and the inflationary Big Bang cosmology of Andre ́ Linde — any event that could happen, however unlikely it might be, must happen somewhere in some other parallel universe.18 So long as life has a positive (greater than zero) probability of arising, it had to arise in some possible world. Therefore, sooner or later some universe had to acquire life-sustaining characteristics. Clifford Longley explains that according to the many-worlds hypothesis:
There could have been millions and millions of different universes created each with different dial settings of the fundamental ratios and constants, so many in fact that the right set was bound to turn up by sheer chance. We just happened to be the lucky ones.19
According to the many-worlds hypothesis, our existence in the universe only appears vastly improbable, since calculations about the improbability of the anthropic coincidences arising by chance only consider the “probabilistic resources” (roughly, the amount of time and the number of possible trials) available within our universe and neglect the probabilistic resources available from the parallel universes. According to the manyworlds hypothesis, chance can explain the existence of life in the universe after all.
The many-worlds hypothesis now stands as the most popular naturalistic explanation for the anthropic fine tuning and thus warrants detailed comment. Though clearly ingenious, the many-worlds hypothesis suffers from an overriding difficulty: we have no evidence for any universes other than our own. Moreover, since possible worlds are by definition causally inaccessible to our own world, there can be no evidence for their existence except that they allegedly render probable otherwise vastly improbable events. Of course, no one can observe a designer directly either, although a theistic designer — that is, God — is not causally disconnected from our world. Even so, recent work by philosophers of science such as Richard Swinburne, John Leslie, Bill Craig,20 Jay Richards,21 and Robin Collins have established several reasons for preferring the (theistic) design hypothesis to the naturalistic many-worlds hypothesis.
2.3 Theistic Design: A Better Explanation?
First, all current cosmological models involving multiple universes require some kind of mechanism for generating universes. Yet such a “universe generator” would itself require precisely configured physical states, thus begging the question of its initial design. As Collins describes the dilemma:
In all currently worked out proposals for what this universe generator could be — such as the oscillating big bang and the vacuum fluctuation models … — the “generator” itself is governed by a complex set of laws that allow it to produce universes. It stands to reason, therefore, that if these laws were slightly different the generator probably would not be able to produce any universes that could sustain life.22
Indeed, from experience we know that some machines (or factories) can produce other machines. But our experience also suggests that such machine-producing machines themselves require intelligent design.
Second, as Collins argues, all things being equal, we should prefer hypotheses “that are natural extrapolations from what we already know” about the causal powers of various kinds of entities.23 Yet when it comes to explaining the anthropic coincidences, the multiple-worlds hypothesis fails this test, whereas the theistic-design hypothesis does not. To illustrate, Collins asks his reader to imagine a paleontologist who posits the existence of an electromagnetic “dinosaur-bone-producing field”, as opposed to actual dinosaurs, as the explanation for the origin of large fossilized bones. While certainly such a field qualifies as a possible explanation for the origin of the fossil bones, we have no experience of such fields or of their producing fossilized bones. Yet we have observed animal remains in various phases of decay and preservation in sediments and sedimentary rock. Thus, most scientists rightly prefer the actual dinosaur hypothesis over the apparent dinosaur hypothesis (that is, the “dinosaur-bone-producing-field” hypothesis) as an explanation for the origin of fossils. In the same way, Collins argues, we have no experience of anything like a “universe generator” (that is not itself designed; see above) producing finely tuned systems or infinite and exhaustively random ensembles of possibilities. Yet we do have extensive experience of intelligent agents producing finely tuned machines such as Swiss watches. Thus, Collins concludes, when we postulate “a supermind” (God) to explain the fine tuning of the universe, we are extrapolating from our experience of the causal powers of known entities (that is, intelligent humans), whereas when we postulate the existence of an infinite number of separate universes, we are not.
Third, as Craig has shown, for the many-worlds hypothesis to suffice as an explanation for anthropic fine tuning, it must posit an exhaustively random distribution of physical parameters and thus an infinite number of parallel universes to insure that a life-producing combination of factors will eventually arise. Yet neither of the physical models that allow for a multiple-universe interpretation — Everett’s quantum-mechanical model or Linde’s inflationary cosmology — provides a compelling justification for believing that such an exhaustively random and infinite number of parallel universes exists, but instead only a finite and nonrandom set.24 The Everett model, for example, only generates an ensemble of material states, each of which exists within a parallel universe that has the same set of physical laws and constants as our own. Since the physical constants do not vary “across universes”, Everett’s model does nothing to increase the probability of the precise fine tuning of constants in our universe arising by chance. Though Linde’s model does envision a variable ensemble of physical constants in each of his individual “bubble universes”, his model fails to generate either an exhaustively random set of such conditions or the infinite number of universes required to render probable the life-sustaining fine tuning of our universe.
Fourth, Richard Swinburne argues that the theistic-design hypothesis constitutes a simpler and less ad hoc hypothesis than the many-worlds hypothesis.25 He notes that virtually the only evidence for many worlds is the very anthropic fine tuning the hypothesis was formulated to explain. On the other hand, the theistic-design hypothesis, though also only supported by indirect evidences, can explain many separate and independent features of the universe that the many-worlds scenario cannot, including the origin of the universe itself, the mathematical beauty and elegance of physical laws, and personal religious experience. Swinburne argues that the God hypothesis is a simpler as well as a more comprehensive explanation because it requires the postulation of only one explanatory entity, rather than the multiple entities — including the finely tuned universe generator and the infinite number of causally separate universes — required by the many-worlds hypothesis.
Swinburne and Collins’ arguments suggest that few reasonable people would accept such an unparsimonious and farfetched explanation as the many-worlds hypothesis in any other domain of life. That some scientists dignify the many-worlds hypothesis with serious discussion may speak more to an unimpeachable commitment to naturalistic philosophy than to any compelling merit for the idea itself. As Clifford Longley noted in the London Times in 1989,26 the use of the many-worlds hypothesis to avoid the theistic-design argument often seems to betray a kind of special pleading and metaphysical desperation. As Longley explains:
The [anthropic-design argument] and what it points to is of such an order of certainty that in any other sphere of science, it would be regarded as settled. To insist otherwise is like insisting that Shakespeare was not written by Shakespeare because it might have been written by a billion monkeys sitting at a billion keyboards typing for a billion years. So it might. But the sight of scientific atheists clutching at such desperate straws has put new spring in the step of theists.27
Indeed, it has. As the twentieth century comes to a close, the design argument has reemerged from its premature retirement at the hands of biologists in the nineteenth century. Physics, astronomy, cosmology, and chemistry have each revealed that life depends on a very precise set of design parameters, which, as it happens, have been built into our universe. The finetuning evidence has led to a persuasive reformulation of the design hypothesis, even if it does not constitute a formal deductive proof of God’s existence. Physicist John Polkinghorne has written that, as a result, “we are living in an age where there is a great revival of natural theology taking place. That revival of natural theology is taking place not on the whole among theologians, who have lost their nerve in that area, but among the scientists.”28 Polkinghorne also notes that this new natural theology generally has more modest ambitions than the natural theology of the Middle Ages. Indeed, scientists arguing for design based upon evidence of anthropic fine tuning tend to do so by inferring an intelligent cause as a “best explanation”, rather than by making a formal deductive proof of God’s existence. (See Appendix, pp. 213–34, “Fruitful Interchange or Polite Chitchat: The Dialogue between Science and Theology”.) Indeed, the foregoing analysis of competing types of causal explanations for the anthropic fine tuning suggests intelligent design precisely as the best explanation for its origin. Thus, fine-tuning evidence may support belief in God’s existence, even if it does not “prove” it in a deductively certain way.
3.1 Evidence of Intelligent Design in Biology
Despite the renewed interest in design among physicists and cosmologists, most biologists are still reluctant to consider such notions. Indeed, since the late-nineteenth century, most biologists have rejected the idea that biological organisms manifest evidence of intelligent design. While many acknowledge the appearance of design in biological systems, they insist that purely naturalistic mechanisms such as natural selection acting on random variations can fully account for the appearance of design in living things.
3.2 Molecular Machines
Nevertheless, the interest in design has begun to spread to biology. For example, in 1998 the leading journal, Cell, featured a special issue on “Macromolecular Machines”. Molecular machines are incredibly complex devices that all cells use to process information, build proteins, and move materials back and forth across their membranes. Bruce Alberts, President of the National Academy of Sciences, introduced this issue with an article entitled, “The Cell as a Collection of Protein Machines”. In it, he stated that:
We have always underestimated cells. … The entire cell can be viewed as a factory that contains an elaborate network of interlocking assembly lines, each of which is composed of a set of large protein machines. … Why do we call the large protein assemblies that underlie cell function protein machines? Precisely because, like machines invented by humans to deal efficiently with the macroscopic world, these protein assemblies contain highly coordinated moving parts.29
Alberts notes that molecular machines strongly resemble machines designed by human engineers, although as an orthodox neo-Darwinian he denies any role for actual, as opposed to apparent, design in the origin of these systems.
In recent years, however, a formidable challenge to this view has arisen within biology. In his book Darwin’s Black Box (1996), Lehigh University biochemist Michael Behe shows that neo-Darwinists have failed to explain the origin of complex molecular machines in living systems. For example, Behe looks at the ion-powered rotary engines that turn the whip-like flagella of certain bacteria.30 He shows that the intricate machinery in this molecular motor — including a rotor, a stator, O-rings, bushings, and a drive shaft — requires the coordinated interaction of some forty complex protein parts. Yet the absence of any one of these proteins results in the complete loss of motor function. To assert that such an “irreducibly complex” engine emerged gradually in a Darwinian fashion strains credulity. According to Darwinian theory, natural selection selects functionally advantageous systems.31 Yet motor function only ensues after all the necessary parts have independently self-assembled — an astronomically improbable event. Thus, Behe insists that Darwinian mechanisms cannot account for the origin of molecular motors and other “irreducibly complex systems” that require the coordinated interaction of multiple independent protein parts.
To emphasize his point, Behe has conducted a literature search of relevant technical journals.32 He has found a complete absence of gradualistic Darwinian explanations for the origin of the systems and motors that he discusses. Behe concludes that neo-Darwinists have not explained, or in most cases even attempted to explain, how the appearance of design in “Irreducibly complex” systems arose naturalistically. Instead, he notes that we know of only one cause sufficient to produce functionally integrated, irreducibly complex systems, namely, intelligent design. Indeed, whenever we encounter irreducibly complex systems and we know how they arose, they were invariably designed by an intelligent agent. Thus, Behe concludes (on strong uniformitarian grounds) that the molecular machines and complex systems we observe in cells must also have had an intelligent source. In brief, molecular motors appear designed because they were designed.
3.3 The Complex Specificity of Cellular Components
As Dembski has shown elsewhere,33 Behe’s notion of “irreducible complexity” constitutes a special case of the “complexity” and “specification” criteria that enables us to detect intelligent design. Yet a more direct application of Dembski’s criteria to biology can be made by analyzing proteins, the macromolecular components of the molecular machines that Behe examines inside the cell. In addition to building motors and other biological structures, proteins perform the vital biochemical functions — information processing, metabolic regulation, signal transduction — necessary to maintain and create cellular life.
During the 1950s, scientists quickly realized that proteins possess another remarkable property. In addition to their complexity, proteins also exhibit specificity, both as one-dimensional arrays and as three-dimensional structures. Whereas proteins are built from rather simple chemical building blocks known as amino acids, their function — whether as enzymes, signal transducers, or structural components in the cell — depends crucially upon the complex but specific sequencing of these building blocks.36 Molecular biologists such as Francis Crick quickly likened this feature of proteins to a linguistic text. Just as the meaning (or function) of an English text depends upon the sequential arrangement of letters in a text, so too does the function of a polypeptide (a sequence of amino acids) depend upon its specific sequencing. Moreover, in both cases, slight alterations in sequencing can quickly result in loss of function.
Biologists, from Darwin’s time to the late 1930s, assumed that proteins had simple, regular structures explicable by reference to mathematical laws. Beginning in the 1950s, however,
biologists made a series of discoveries that caused this simplistic view of proteins to change. Molecular biologist Fred Sanger determined the sequence of constituents in the protein molecule insulin. Sanger’s work showed that proteins are made of long nonrepetitive sequences of amino acids, rather like an irregular arrangement of colored beads on a string.34 Later in the 1950s, work by John Kendrew on the structure of the protein myoglobin showed that proteins also exhibit a surprising three-dimensional complexity. Far from the simple structures that biologists had imagined, Kendrew’s work revealed an extraordinarily complex and irregular three-dimensional shape — a twisting, turning, tangled chain of amino acids. As Kendrew explained in 1958, “the big surprise was that it was so irregular … the arrangement seems to be almost totally lacking in the kind of regularity one instinctively anticipates, and it is more complicated than has been predicted by any theory of protein structure.”35
In the biological case, the specific sequencing of amino acids gives rise to specific three-dimensional structures. This structure or shape in turn (largely) determines what function, if any, the amino acid chain can perform within the cell. A functioning protein’s three-dimensional shape gives it a “hand-in-glove” fit with other molecules in the cell, enabling it to catalyze specific chemical reactions or to build specific structures within the cell. Due to this specificity, one protein cannot usually substitute for another any more than one tool can substitute for another. A topoisomerase can no more perform the job of a polymerase, than a hatchet can perform the function of a soldering iron. Proteins can perform functions only by virtue of their three-dimensional specificity of fit with other equally specified and complex molecules within the cell. This threedimensional specificity derives in turn from a one-dimensional specificity of sequencing in the arrangement of the amino acids that form proteins.
3.4. The Sequence Specificity of DNA
According to Crick’s hypothesis, the specific arrangement of the nucleotide bases on the DNA molecule generates the specific arrangement of amino acids in proteins.41 The sequence hypothesis suggested that the nucleotide bases in DNA functioned like letters in an alphabet or characters in a machine code. Just as alphabetic letters in a written language may perform a communication function depending upon their sequencing, so too, Crick reasoned, the nucleotide bases in DNA may result in the production of a functional protein molecule depending upon their precise sequential arrangement. In both cases, function depends crucially upon sequencing. The nucleotide bases in DNA function in precisely the same way as symbols in a machine code or alphabetic characters in a book. In each case, the arrangement of the characters determines the function of the sequence as a whole. As Dawkins notes, “The machine code of the genes is uncannily computerlike.”42 Or, as software innovator Bill Gates explains, “DNA is like a computer program, but far, far more advanced than any software we’ve ever created.”43 In the case of a computer code, the specific arrangement of just two symbols (0 and 1) suffices to carry information. In the case of an English text, the twenty-six letters of the alphabet do the job. In the case of DNA, the complex but precise sequencing of the four nucleotide bases adenine, thymine, guanine, and cytosine (A, T, G, and C)—stores and transmits genetic information, information that finds expression in the construction of specific proteins. Thus, the sequence hypothesis implied not only the complexity but also the functional specificity of DNA base sequencing.
The discovery of the complexity and specificity of proteins has raised an important question. How did such complex but specific structures arise in the cell? This question recurred with particular urgency after Sanger revealed his results in the early 1950s. Clearly, proteins were too complex and functionally specific to arise “by chance”. Moreover, given their irregularity, it seemed unlikely that a general chemical law or regularity governed their assembly. Instead, as Nobel Prize winner Jacques Monod recalled, molecular biologists began to look for some source of information within the cell that could direct the construction of these highly specific structures. As Monod would later recall, to explain the presence of the specific sequencing of proteins, “you absolutely needed a code.”37
In 1953, James Watson and Francis Crick elucidated the structure of the DNA molecule.38 The structure they discovered suggested a means by which information or “specificity” of sequencing might be encoded along the spine of DNA’s sugar-phosphate backbone.39 Their model suggested that variations in sequencing of the nucleotide bases might find expression in the sequencing of the amino acids that form proteins. Francis Crick proposed this idea in 1955, calling it the “sequence hypothesis”.40
4.1 The Origin of Life and the Origin of Biological Information (or Specified Complexity)
Developments in molecular biology have led scientists to ask how the specific sequencing — the information content or specified complexity — in both DNA and proteins originated. These developments have also created severe difficulties for all strictly naturalistic theories of the origin of life. Since the late 1920s, naturalistically minded scientists have sought to explain the origin of the very first life as the result of a completely undirected process of “chemical evolution”. In The Origin of Life (1938), Alexander I. Oparin, a pioneering chemical evolutionary theorist, envisioned life arising by a slow process of transformation starting from simple chemicals on the early earth. Unlike Darwinism, which sought to explain the origin and diversification of new and more complex living forms from simpler, preexisting forms, chemical evolutionary theory seeks to explain the origin of the very first cellular life. Yet since the late 1950s, naturalistic chemical evolutionary theories have been unable to account for the origin of the complexity and specificity of DNA base sequencing necessary to build a living cell.44 This section will, using the categories of Dembski’s explanatory filter, evaluate the competing types of naturalistic explanations for the origin of specified complexity or information content necessary to the first living cell.
4.2 Beyond the Reach of Chance
Perhaps the most common popular view about the origin of life is that it happened by chance. A few scientists have also voiced support for this view at various times during their careers. In1954 physicist George Wald, for example, argued for the causal efficacy of chance operating over vast expanses of time. As he stated, “Time is in fact the hero of the plot. … Given so much time, the impossible becomes possible, the possible probable, and the probable virtually certain.”45 Later Francis Crick would suggest that the origin of the genetic code — that is, the translation system — might be a “frozen accident”.46 Other theories have invoked chance as an explanation for the origin of genetic information, often in conjunction with prebiotic natural selection. (See section 4.3.)
While some scientists may still invoke “chance” as an explanation, most biologists who specialize in origin-of-life research now reject chance as a possible explanation for the origin of the information in DNA and proteins.47 Since molecular biologists began to appreciate the sequence specificity of proteins and nucleic acids in the 1950s and 1960s, many calculations have been made to determine the probability of formulating functional proteins and nucleic acids at random. Various methods of calculating probabilities have been offered by Morowitz,48 Hoyle and Wickramasinghe,49 Cairns-Smith,50 Prigogine,51 and Yockey.52 For the sake of argument, such calculations have often assumed extremely favorable prebiotic conditions (whether realistic or not), much more time than there was actually available on the early earth, and theoretically maximal reaction rates among constituent monomers (that is, the constituent parts of proteins, DNA and RNA). Such calculations have invariably shown that the probability of obtaining functionally sequenced biomacromolecules at random is, in Prigogine’s words, “vanishingly small … even on the scale of … billions of years”.53 As Cairns-Smith wrote in 1971:
Blind chance … is very limited. Low-levels of cooperation he [blind chance] can produce exceedingly easily (the equivalent of letters and small words), but he becomes very quickly incompetent as the amount of organization increases. Very soon indeed long waiting periods and massive material resources become irrelevant.54
Consider the probabilistic hurdles that must be overcome to construct even one short protein molecule of about one hundred amino acids in length. (A typical protein consists of about three hundred amino acid residues, and many crucial proteins are very much longer.)55
First, all amino acids must form a chemical bond known as a peptide bond so as to join with other amino acids in the protein chain. Yet in nature many other types of chemical bonds are possible between amino acids; in fact, peptide and nonpeptide bonds occur with roughly equal probability. Thus, at any given site along a growing amino acid chain the probability of having a peptide bond is roughly 1/2. The probability of attaining four peptide bonds is: (1/2 × 1/2 × 1/2 × 1/2) = 1/16or (1/2)4. The probability of building a chain of one hundred amino acids in which all linkages involve peptide linkages is (1/2)99, or roughly 1 chance in 1030.
Secondly, in nature every amino acid has a distinct mirror image of itself, one left-handed version, or L-form, and one right-handed version, or D-form. These mirror-image forms are called optical isomers. Functioning proteins use only lefthanded amino acids, yet the right-handed and left-handed isomers occur in nature with roughly equal frequency. Taking this into consideration compounds the improbability of attaining a biologically functioning protein. The probability of attaining at random only L-amino acids in a hypothetical peptide chain one hundred amino acids long is (1/2)100, or again roughly 1 chance in 1030. The probability of building a one hundred-amino-acidlength chain at random in which all bonds are peptide bonds and all amino acids are L-form would be roughly 1 chance in 1060.
Finally, functioning proteins have a third independent requirement, which is the most important of all; their amino acids must link up in a specific sequential arrangement, just as the letters in a sentence must be arranged in a specific sequence to be meaningful. In some cases, even changing one amino acid at a given site can result in a loss of protein function. Moreover, because there are twenty biologically occurring amino acids, the probability of getting a specific amino acid at a given site is small, that is, 1/20. (Actually the probability is even lower because there are many nonproteineous amino acids in nature.) On the assumption that all sites in a protein chain require one particular amino acid, the probability of attaining a particular protein one hundred amino acids long would be (1/20)100, or roughly 1 chance in 10130. We know now, however, that some sites along the chain do tolerate several of the twenty proteineous amino acids, while others do not. The biochemist Robert Sauer of MIT has used a technique known as “cassette mutagenesis” to determine just how much variance among amino acids can be tolerated at any given site in several proteins. His results have shown that, even taking the possibility of variance into account, the probability of achieving a functional sequence of amino acids56 in several known proteins at random is still “vanishingly small”, roughly 1 chance in 1065 — an astronomically large number.57 (There are 1065 atoms in our galaxy.)58
Moreover, if one also factors in the need for proper bonding and homochirality (the first two factors discussed above), the probability of constructing a rather short functional protein at random becomes so small (1 chance in 10125) as to approach the universal probability bound of 1 chance in 10150, the point at which appeals to chance become absurd given the “probabilistic resources” of the entire universe.59 Further, making the same calculations for even moderately longer proteins easily pushes these numbers well beyond that limit. For example, the probability of generating a protein of only 150 amino acids in length exceeds (using the same method as above)60 1 chance in 10180, well beyond the most conservative estimates for the small probability bound given our multi-billion-year-old universe.61 In other words, given the complexity of proteins, it is extremely unlikely that a random search through all the possible amino acid sequences could generate even a single relatively short functional protein in the time available since the beginning of the universe (let alone the time available on the early earth). Conversely, to have a reasonable chance of finding a short functional protein in such a random search would require vastly more time than either cosmology or geology allows.
More realistic calculations (taking into account the probable presence of non proteineous amino acids, the need for vastly longer functional proteins to perform specific functions such as polymerization, and the need for multiple proteins functioning in coordination) only compound these improbabilities — indeed, almost beyond computability. For example, recent theoretical and experimental work on the so-called “minimal complexity” required to sustain the simplest possible living organism suggests a lower bound of some 250 to 400 genes and their corresponding proteins.62 The nucleotide sequence space corresponding to such a system of proteins exceeds 4300000. The improbability corresponding to this measure of molecular complexity again vastly exceeds 1 chance in 10150, and thus the “probabilistic resources” of the entire universe.63 Thus, when one considers the full complement of functional biomolecules required to maintain minimal cell function and vitality, one can see why chance-based theories of the origin of life have been abandoned. What Mora said in 1963 still holds:
Statistical considerations, probability, complexity, etc., followed to their logical implications suggest that the origin and continuance of life is not controlled by such principles. An admission of this is the use of a period of practically infinite time to obtain the derived result. Using such logic, however, we can prove anything.64
Though the probability of assembling a functioning biomolecule or cell by chance alone is exceedingly small, origin-of-life researchers have not generally rejected the chance hypothesis merely because of the vast improbabilities associated with these events. Many improbable things occur every day by chance. Any hand of cards or any series of rolled dice will represent a highly improbable occurrence. Yet observers often justifiably attribute such events to chance alone. What justifies the elimination of the chance is not just the occurrence of a highly improbable event, but the occurrence of a very improbable event that also conforms to an independently given or discernible pattern. If someone repeatedly rolls two dice and turns up a sequence such as: 9, 4, 11, 2, 6, 8, 5, 12, 9, 2, 6, 8, 9, 3, 7, 10, 11, 4, 8 and 4, no one will suspect anything but the interplay of random forces, though this sequence does represent a very improbable event given the number of combinatorial possibilities that correspond to a sequence of this length. Yet rolling twenty (or certainly two hundred!) consecutive sevens will justifiably arouse suspicion that something more than chance is in play. Statisticians have long used a method for determining when to eliminate the chance hypothesis that involves prespecifying a pattern or “rejection region”.65 In the dice example above, one could prespecify the repeated occurrence of seven as such a pattern in order to detect the use of loaded dice, for example. Dembski’s work discussed above has generalized this method to show how the presence of any conditionally independent pattern, whether temporally prior to the observation of an event or not, can help (in conjunction with a small probability event) to justify rejecting the chance hypothesis.66
Origin-of-life researchers have tacitly, and sometimes explicitly, employed precisely this kind of statistical reasoning to justify the elimination of scenarios that rely heavily on chance. Christian de Duve, for example, has recently made this logic explicit in order to explain why chance fails as an explanation for the origin of life:
A single, freak, highly improbable event can conceivably happen. Many highly improbable events—drawing a winning lottery number or the distribution of playing cards in a hand of bridge — happen all the time. But a string of improbable events — drawing the same lottery number twice, or the same bridge hand twice in a row — does not happen naturally.67
De Duve and other origin-of-life researchers have long recognized that the cell represents not only a highly improbable but also a functionally specified system. For this reason, by the mid-1960s most researchers had eliminated chance as a plausible explanation for the origin of the information content or specified complexity necessary to build a cell.68 Many have instead sought other types of naturalistic explanations (see below).
4.3 Prebiotic Natural Selection: A Contradiction in Terms
Of course, even early theories of chemical evolution did not rely exclusively on chance as a causal mechanism. For example, A. I. Oparin’s original theory of evolutionary abiogenesis first published in the 1920s and 1930s invoked prebiotic natural selection as a complement to chance interactions. Oparin’s theory envisioned a series of chemical reactions that he thought would enable a complex cell to assemble itself gradually and naturalistically from simple chemical precursors.
For the first stage of chemical evolution, Oparin proposed that simple gases such as ammonia (NH3), methane (CH4), water (H2O), carbon dioxide (CO2), and hydrogen (H2) would have rained down to the early oceans and combined with metallic compounds extruded from the core of the earth.69 With the aid of ultraviolet radiation from the sun, the ensuing reactions would have produced energy-rich hydrocarbon compounds.70 These in turn would have combined and recombined with various other compounds to make amino acids, sugars, phosphates, and other “building blocks” of the complex molecules (such as proteins) necessary to living cells.71 These constituents would eventually arrange themselves by chance into primitive metabolic systems within simple celllike enclosures that Oparin called coacervates.72 Oparin then proposed a kind of Darwinian competition for survival among his coacervates. Those that, by chance, developed increasingly complex molecules and metabolic processes would have survived to grow more complex and efficient. Those that did not would have dissolved.73 Thus, Oparin invoked differential survival or natural selection as a mechanism for preserving entities of increasing complexity, thus allegedly helping to overcome the difficulties attendant upon pure-chance hypotheses.
Nevertheless, developments in molecular biology during the 1950s cast doubt on this theory. Oparin originally invoked natural selection to explain how cells refined primitive metabolism once it had arisen. His scenario relied heavily, therefore, on chance to explain the initial formation of the constituent biomacromolecules (such as proteins and DNA) upon which any cellular metabolism would depend. The discovery of the extreme complexity and specificity of these molecules during the 1950s undermined the plausibility of this claim. For this reason, Oparin published a revised version of his theory in 1968 that envisioned a role for natural selection earlier in the process of abiogenesis. His new theory claimed that natural selection acted upon random polymers as they formed and changed within his coacervate protocells.74 As more complex and efficient molecules accumulated, they would have survived and reproduced more prolifically.
Even so, Oparin’s concept of natural selection acting on initially nonliving chemicals (that is, prebiotic natural selection) remained problematic. For one thing, it seemed to presuppose a preexisting mechanism of self-replication. Yet self-replication in all extant cells depends upon functional and, therefore, highly sequence-specific proteins and nucleic acids. Yet the origin of specificity in these molecules is precisely what Oparin needed to explain. As Christian de Duve has written, theories of prebiotic natural selection “need information which implies they have to presuppose what is to be explained in the first place”.75 Oparin attempted to circumvent this problem by claiming that the sequences of monomers in the first polymers need not have been highly specific in their arrangement. But this claim raised doubts about whether an accurate mechanism of self-replication (and, thus, natural selection) could have functioned at all. Indeed, Oparin’s scenario did not reckon on a phenomenon known as “error catastrophe”, in which small “errors” or deviations from functionally necessary sequencing are quickly amplified in successive replications.76
Thus, the need to explain the origin of specified complexity in biomacromolecules created an intractable dilemma for Oparin. On the one hand, if he invoked natural selection late in his scenario, then he would in effect attribute the origin of the highly complex and specified biomolecules (necessary to a self-replicating system) to chance alone. Yet, as the mathematician Von Neumann77 would show, any system capable of self-replication would need to contain subsystems that were functionally equivalent to the information storage, replicating, and processing systems found in extant cells. His calculations and similar ones by Wigner,78 Landsberg,79 and Morowitz80 showed that random fluctuations of molecules in all probability (to understate the case) would not produce the minimal complexity needed for even a primitive replication system.
On the other hand, if Oparin invoked natural selection earlier in the process of chemical evolution, before functional specificity in biomacromolecules had arisen, he could not offer any explanation for how self-replication and thus natural selection could have even functioned. Natural selection presupposes a self-replicating system, but self-replication requires functioning nucleic acids and proteins (or molecules approaching their specificity and complexity) — the very entities Oparin needed to explain. For this reason, the evolutionary biologist Dobzhansky would insist, “prebiological natural selection is a contradiction in terms”.81 Indeed, as a result of this dilemma, most researchers rejected the postulation of prebiotic natural selection as either question begging or indistinguishable from implausible chance-based hypotheses.82
Nevertheless, Richard Dawkins83 and Bernd-Olaf Küppers84 have recently attempted to resuscitate prebiotic natural selection as an explanation for the origin of biological information. Both accept the futility of naked appeals to chance and invoke what Küppers calls a “Darwinian optimization principle”. Both use a computer to demonstrate the efficacy of prebiotic natural selection. Each selects a target sequence to represent a desired functional polymer. After creating a crop of randomly constructed sequences and generating variations among them at random, their computers select those sequences that match the target sequence most closely. The computers then amplify the production of those sequences, eliminate the others (to simulate differential reproduction), and repeat the process. As Ku ̈ppers puts it, “Every mutant sequence that agrees one bit better with the meaningful or reference sequence … will be allowed to reproduce more rapidly.”85 In his case, after a mere thirty-five generations, his computer succeeds in spelling his target sequence, “NATURAL SELECTION”.
Despite superficially impressive results, these “simulations” conceal an obvious flaw: molecules in situ do not have a target sequence “in mind”. Nor will they confer any selective advantage on a cell, and thus differentially reproduce, until they combine in a functionally advantageous arrangement. Thus, nothing in nature corresponds to the role that the computer plays in selecting functionally nonadvantageous sequences that happen to agree “one bit better” than others with a target sequence. The sequence “NORMAL ELECTION” may agree more with “NATURAL SELECTION” than does the sequence “MISTRESS DEFECTION”, but neither of the two yields any advantage in communication over the other, if, that is, we are trying to communicate something about “NATURAL SELECTION”. If so, both are equally ineffectual. Similarly, a nonfunctional polypeptide would confer no selective advantage on a hypothetical proto-cell, even if its sequence happens to “agree one bit better” with an unrealized target protein than some other nonfunctional polypeptide.
And, indeed, both Küppers’86 and Dawkins’87 published results of their simulations show the early generations of variant phrases awash in nonfunctional gibberish.88 In Dawkins’ simulation, not a single functional English word appears until after the tenth iteration (unlike the more generous example above, which starts with actual, albeit incorrect, words). Yet to make distinctions on the basis of function among sequences that have no function whatsoever would seem quite impossible. Such determination can only be made if considerations of proximity to possible future function are allowed, but this requires foresight that natural selection does not have. But a computer, programmed by a human being, can perform these functions. To imply that molecules can as well only illicitly personifies nature. Thus, if these computer simulations demonstrate anything, they subtly demonstrate the need for intelligent agents to elect some options and exclude others — that is, to create information.
4.4 Self-Organizational Scenarios
Because of the difficulties with chance-based theories, including those that rely upon prebiotic natural selection, most origin-of-life theorists after the mid-1960s attempted to explain the origin of biological information in a completely different way. Researchers began to look for “so-called” selforganizational laws and properties of chemical attraction that might explain the origin of the specified complexity or information content in DNA and proteins. Rather than invoking chance, these theories invoked necessity. Indeed, if neither chance nor prebiotic natural selection acting on chance suffices to explain the origin of large amounts of specified biological information, then scientists committed to finding a naturalistic explanation for the origin of life have needed to rely on principles of physical or chemical necessity. Given a limited number of explanatory options (chance, and/or necessity, or design), the inadequacy of chance has, for many researchers, left only one option. Christian de Duve articulates the logic:
A string of improbable events — drawing the same lottery number twice, or the same bridge hand twice in a row — does not happen naturally. All of which lead me to conclude that life is an obligatory manifestation of matter, bound to arise where conditions are appropriate.89
By the late 1960s origin-of-life biologists began to consider the self-organizational perspective that de Duve describes. At that time, several researchers began to propose that deterministic forces (that is, “necessity”) made the origin of life not just probable but inevitable. Some suggested that simple chemicals might possess “self-ordering properties” capable of organizing the constituent parts of proteins, DNA, and RNA into the specific arrangements they now possess.90 Steinman and Cole, for example, suggested that differential bonding affinities or forces of chemical attraction between certain amino acids might account for the origin of the sequence specificity of proteins.91Just as electrostatic forces draw sodium (Na+) and chloride ions (Cl–) together into highly ordered patterns within a crystal of salt (NaCl), so too might amino acids with special affinities for each other arrange themselves to form proteins. Kenyon and Steinman developed this idea in a book entitled Biochemical Predestination in 1969. They argued that life might have been “biochemically predestined” by the properties of attraction that exist between its constituent chemical parts, particularly between the amino acids in proteins.92
In 1977, Prigogine and Nicolis proposed another self-organizational theory based on a thermodynamic characterization of living organisms. In Self-Organization in Nonequilibrium Systems, Prigogine and Nicolis classified living organisms as open, nonequilibrium systems capable of “dissipating” large quantities of energy and matter into the environment.93 They observed that open systems driven far from equilibrium often display self-ordering tendencies. For example, gravitational energy will produce highly ordered vortices in a draining bathtub; thermal energy flowing through a heat sink will generate distinctive convection currents or “spiral wave activity”. Prigogine and Nicolis argued that the organized structures observed in living systems might have similarly “self-originated” with the aid of an energy source. In essence, they conceded the improbability of simple building blocks arranging themselves into highly ordered structures under normal equilibrium conditions. But they suggested that, under nonequilibrium conditions, where an external source of energy is supplied, biochemical building blocks might arrange themselves into highly ordered patterns.
More recently, Kauffman94 and de Duve95 have proposed less detailed self-organizational theories to explain the origin of specified genetic information. Kauffman invokes so-called “autocatalytic properties” that he envisions may emerge from very particular configurations of simple molecules in a rich “chemical minestrone”. De Duve envisions proto-metabolism emerging first with genetic information arising later as a by-product of simple metabolic activity. He invokes an extra-evidential principle, his so-called “Cosmic Imperative”, to render the emergence of molecular complexity more plausible.
4.5 Order v. Information
For many current origin-of-life scientists self-organizational models now seem to offer the most promising approach to explaining the origin of specified biological information. Nevertheless, critics have called into question both the plausibility and the relevance of self-organizational models. Ironically, a prominent early advocate of self-organization, Dean Kenyon, has now explicitly repudiated such theories as both incompatible with empirical findings and theoretically incoherent.96
First, empirical studies have shown that some differential affinities do exist between various amino acids (that is, particular amino acids do form linkages more readily with some amino acids than others).97 Nevertheless, these differences do not correlate to actual sequencing in large classes of known proteins.98 In short, differing chemical affinities do not explain the multiplicity of amino acid sequences that exist in naturally occurring proteins or the sequential arrangement of amino acids in any particular protein.
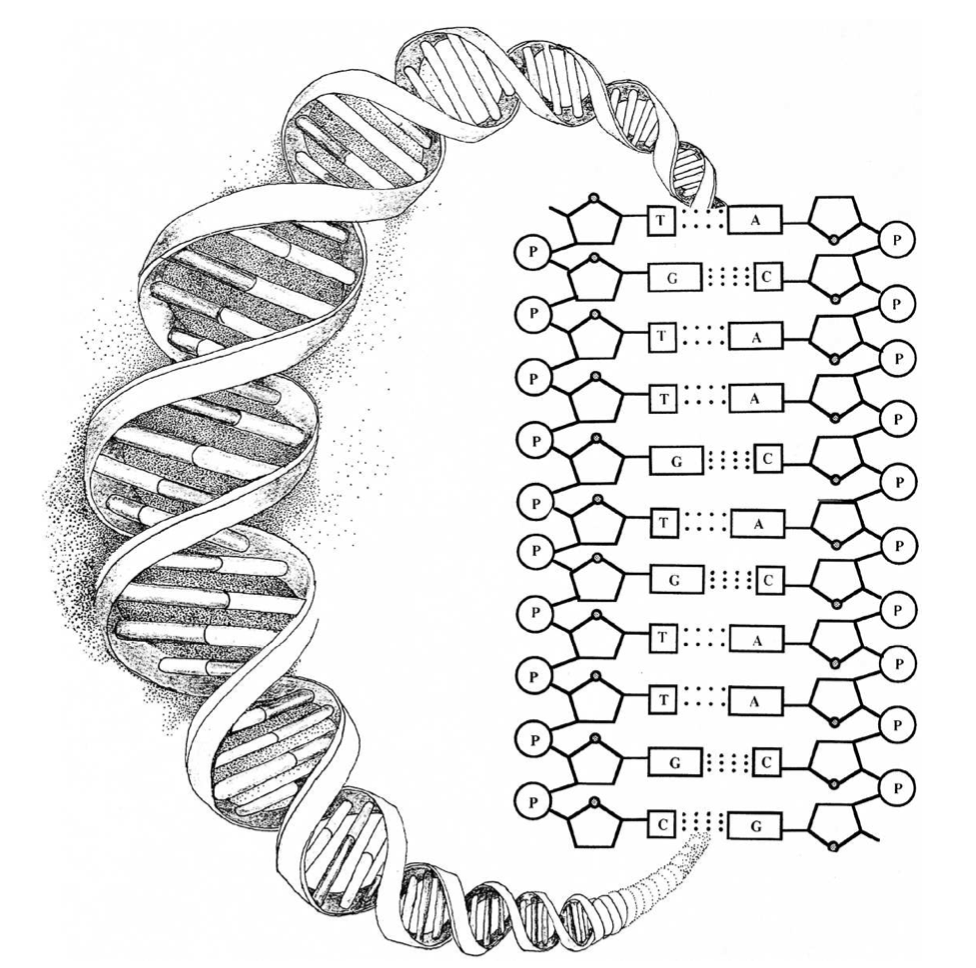
In the case of DNA this point can be made more dramatically. The accompanying illustration [p. 84] shows that the structure of DNA depends upon several chemical bonds. There are bonds, for example, between the sugar and the phosphate molecules that form the two twisting backbones of the DNA molecule. There are bonds fixing individual (nucleotide) bases to the sugar-phosphate backbones on each side of the molecule. There are also hydrogen bonds stretching horizontally across the molecule between nucleotide bases making so-called complementary pairs. These bonds, which hold two complementary copies of the DNA message text together, make replication of the genetic instructions possible. Most importantly, however, notice that there are no chemical bonds between the bases along the vertical axis in the center of the helix. Yet it is precisely along this axis of the molecule that the genetic information in DNA is stored.99
Further, just as magnetic letters can be combined and recombined in any way to form various sequences on a metal surface, so too can each of the four bases A, T, G, and C attach to any site on the DNA backbone with equal facility, making all sequences equally probable (or improbable). Indeed, there are no significant differential affinities between any of the four bases and the binding sites along the sugar-phosphate backbone. The same type of (“n-glycosidic”) bond occurs between the base and the backbone regardless of which base attaches. All four bases are acceptable; none is preferred. As Ku ̈ ppers has noted, “the properties of nucleic acids indicate that all the combinatorially possible nucleotide patterns of a DNA are, from a chemical point of view, equivalent.”100 Thus, “self-organizing” bonding affinities cannot explain the sequentially specific arrangement of nucleotide bases in DNA because: (1) there are no bonds between bases along the message-bearing axis of the molecule, and (2) there are no differential affinities between the backbone and the specific bases that can account for variations in sequencing. Because the same holds for RNA molecules, the theory that life began in an “RNA world” has also failed to solve the sequencing problem101 — the problem of explaining how specific sequencing in functioning RNA molecules could have arisen in the first place.
For those who want to say that life arose as the result of selforganizing properties intrinsic to the material constituents of living systems, these rather elementary facts of molecular biology have decisive implications. The most obvious place to look for self-organizing properties to explain the origin of genetic information is in the constituent parts of the molecules that carry that information. But biochemistry and molecular biology make clear that forces of attraction between the constituents in DNA, RNA, and proteins do not explain the sequence specificity of these large information-bearing biomolecules.
We know this, in addition to the reasons already stated, because of the multiplicity of variant polypeptides and gene sequences that exist in nature and can be synthesized in the laboratory. The properties of the monomers constituting nucleic acids and proteins simply do not make a particular gene, let alone life as we know it, inevitable. Yet if self-organizational scenarios for the origin of biological information are to have any theoretical import, they must claim just the opposite. And, indeed, they often do, albeit without much specificity. As de Duve has put it, “the processes that generated life” were “highly deterministic”, making life as we know it “inevitable” given “the conditions that existed on the prebiotic earth”.102 Yet if we imagine the most favorable prebiotic conditions — a pool of all four DNA nucleotides and all the necessary sugars and phosphates—would any particular genetic sequence have to arise? Given all necessary monomers, would any particular functional protein or gene, let alone a specific genetic code, replication system, or signal transduction circuitry, have to arise? Clearly not.
In the parlance of origin-of-life research, monomers are “building blocks”. And building blocks can be arranged and rearranged in innumerable ways. The properties of blocks do not determine their arrangement in the construction of buildings. Similarly, the properties of biological building blocks do not determine the arrangement of functional polymers. Instead, the chemical properties of the monomers allow for a vast ensemble of possible configurations, the overwhelming majority of which have no biological function whatsoever. Functional genes or proteins are no more inevitable given the properties of their “building blocks” than the palace of Versailles, for example, was inevitable given the properties of the bricks and stone used to construct it. To anthropomorphize, neither bricks and stone nor letters in a written text nor nucleotide bases “care” how they are arranged. In each case, the properties of the constituents remain largely indifferent to the many specific configurations or sequences that they may adopt. Conversely, the properties of nucleotide bases and amino acids do not make any specific sequences “inevitable” as self-organizationalists must claim.
Significantly, information theory makes clear that there is a good reason for this. If chemical affinities between the constituents in the DNA determined the arrangement of the bases, such affinities would dramatically diminish the capacity of DNA to carry information. Consider, for example, what would happen if the individual nucleotide “bases” (A, T, G, C) in a DNA molecule did interact by chemical necessity with each other. Every time adenine (A) occurred in a growing genetic sequence, it would attract thymine (T) to it.103 Every time cytosine (C) appeared, guanine (G) would likely follow. As a result, the DNA would be peppered with repetitive sequences of A’s followed by T’s and C’s followed by G’s. Rather than a genetic molecule capable of virtually unlimited novelty and characterized by unpredictable and aperiodic sequencing, DNA would contain sequences awash in repetition or redundancy—much like the sequences in crystals. In a crystal the forces of mutual chemical attraction do determine, to a very considerable extent, the sequential arrangement of its constituent parts. As a result, sequencing in crystals is highly ordered and repetitive but neither complex nor informative. Once one has seen “Na” followed by “Cl” in a crystal of salt, for example, one has seen the extent of the sequencing possible. In DNA, however, where any nucleotide can follow any other, a vast array of novel sequences is possible, corresponding to a multiplicity of amino acid sequences.
The forces of chemical necessity produce redundancy or monotonous order but reduce complexity and thus the capacity to convey novel information. Thus, as the chemist Michael Polanyi noted:
Suppose that the actual structure of a DNA molecule were due to the fact that the bindings of its bases were much stronger than the bindings would be for any other distribution of bases, then such a DNA molecule would have no information content. Its code-like character would be effaced by an overwhelming redundancy. … Whatever may be the origin of a DNA configuration, it can function as a code only if its order is not due to the forces of potential energy. It must be as physically indeterminate as the sequence of words is on a printed page [emphasis added].104
In other words, if chemists had found that bonding affinities between the nucleotides in DNA produced nucleotide sequencing, they would also have found that they had been mistaken about DNA’s information-bearing properties. Or, to put the point quantitatively, to the extent that forces of attraction between constituents in a sequence determine the arrangement of the sequence, to that extent will the information-carrying capacity of the system be diminished or effaced (by redundancy).105 As Dretske has explained:
As p(si) [the probability of a condition or state of affairs] approaches 1 the amount of information associated with the occurrence of si goes to 0. In the limiting case when the probability of a condition or state of affairs is unity [p(si) = 1], no information is associated with, or generated by, the occurrence of si. This is merely another way to say that no information is generated by the occurrence of events for which there are no possible alternatives.106
Bonding affinities, to the extent they exist, inhibit the maximization of information107 because they determine specific outcomes that will follow specific conditions with high probability. Information-carrying capacity is maximized when just the opposite situation obtains, namely, when antecedent conditions allow many improbable outcomes.
Of course, the sequences of bases in DNA do not just possess information-carrying capacity or syntactic information or information as measured by classical Shannon information theory. These sequences store functionally specified information or specified complexity — that is, they are specified as well as complex. Clearly, however, a sequence cannot be both specified and complex if it is not at least complex. Therefore, the self-organizational forces of chemical necessity that produce redundant order and preclude complexity also preclude the generation of specified complexity (or information content) as well. Chemical affinities do not generate complex sequences. Thus, they cannot be invoked to explain the origin of specified complexity or information content.
The tendency to conflate the qualitative distinctions between “order” and “complexity” has characterized self-organizational research efforts and calls into question the relevance of such work to the origin of life. As Yockey notes, the accumulation of structural or chemical order does not explain the origin of biological complexity or genetic information.108 He concedes that energy flowing through a system may produce highly ordered patterns. Strong winds form swirling tornadoes and the “eyes” of hurricanes; Prigogine’s thermal baths do develop interesting “convection currents”; and chemical elements do coalesce to form crystals. Self-organizational theorists explain well what does not need explaining. What needs explaining in biology is not the origin of order (defined as symmetry or repetition), but the origin of the information content — the highly complex, aperiodic, and yet specified sequences that make biological function possible. As Yockey warns:
Attempts to relate the idea of order … with biological organization or specificity must be regarded as a play on words which cannot stand careful scrutiny. Informational macromolecules can code genetic messages and therefore can carry information because the sequence of bases or residues is affected very little, if at all, by [self-organizing] physico-chemical factors.109
In the face of these difficulties, some self-organizational theorists have claimed that we must await the discovery of new natural laws to explain the origin of biological information. As Manfred Eigen has argued, “our task is to find an algorithm, a natural law, that leads to the origin of information.”110 But this suggestion betrays confusion on two counts. First, scientific laws do not generally explain or cause natural phenomena; they describe them. For example, Newton’s law of gravitation described, but did not explain, the attraction between planetary bodies. Second, laws necessarily describe highly deterministic or predictable relationships between antecedent conditions and consequent events. Laws describe patterns in which the probability of each successive event (given the previous event and the action of the law) becomes inevitable. Yet information mounts as improbabilities multiply. Thus, to say that scientific laws describe complex informational patterns is essentially a contradiction in terms. Instead, scientific laws describe (almost by definition) highly predictable and regular phenomena — that is, redundant order, not complexity (whether specified or otherwise).
5.1 The Return of the Design Hypothesis
If neither chance nor principles of physical-chemical necessity, nor the two acting in combination, explain the ultimate origin of specified complexity or information content in DNA, what does? Do we know of any entity that has the causal powers to create large amounts of specified complexity or information content? We do. As Henry Quastler, an early pioneer in the application of information theory to molecular biology, recognized, the “creation of new information is habitually associated with conscious activity”.111
Indeed, experience affirms that specified complexity or information content not only routinely arises but always arises from the activity of intelligent minds. When a computer user traces the information on a screen back to its source, he invariably comes to a mind — a software engineer or programmer. If a reader traces the information content in a book or newspaper column back to its source, he will find a writer — again a mental, not a material, cause. Our experientially based knowledge of information confirms that systems with large amounts112 of specified complexity or information content (especially codes and languages) always originate from an intelligent source — that is, from mental or personal agents. Moreover, this generalization holds not only for the specified complexity or information present in natural languages but also for other forms of specified complexity, whether present in machine codes, machines, or works of art. Like the letters in a section of meaningful text, the parts in a working engine represent a highly improbable and functionally specified configuration. Similarly, the highly improbable shapes in the rock on Mount Rushmore in the United States conform to an independently given pattern — the face of American presidents known from books and paintings. Thus, both these systems have a large amount ofspecified complexity or information content. Not coincidentally, they also resulted from intelligent design, not chance and/or physical-chemical necessity.
This generalization about the cause of specified complexity or information has, ironically, received confirmation from origin-of-life research itself. During the last forty years, every naturalistic model (see n. 44 above) proposed has failed precisely to explain the origin of the specified genetic information required to build a living cell. Thus, mind or intelligence, or what philosophers call “agent causation”, now stands as the only cause known to be capable of generating large amounts of specified complexity or information content (from nonbiological precursors).
Indeed, because large amounts of specified complexity or information content must be caused by a mind or intelligent design, one can detect the past action of an intelligent cause from the presence of an information-rich effect, even if the cause itself cannot be directly observed.113 For instance, visitors to the gardens of Victoria harbor in Canada correctly infer the activity of intelligent agents when they see a pattern of red and yellow flowers spelling “Welcome to Victoria”, even if they did not see the flowers planted and arranged. Similarly, the specifically arranged nucleotide sequences — the complex but functionally specified sequences — in DNA imply the past action of an intelligent mind, even if such mental agency cannot be directly observed.
Moreover, the logical calculus underlying such inferences follows a valid and well-established method used in all historical and forensic sciences. In historical sciences, knowledge of the present causal powers of various entities and processes enables scientists to make inferences about possible causes in the past. When a thorough study of various possible causes turns up just a single adequate cause for a given effect, historical or forensic scientists can make fairly definitive inferences about the past.114 Inferences based on knowledge of necessary causes (“distinctive diagnostics”) are common in historical and forensic sciences and often lead to the detection of intelligent as well as natural causes. Since criminal X’s fingers are the only known cause of criminal X’s fingerprints, X’s prints on the murder weapon incriminate him with a high degree of certainty. In the same way, since intelligent design is the only known cause of large amounts of specified complexity or information content, the presence of such information implicates an intelligent source.
Scientists in many fields recognize the connection between intelligence and specified complexity and make inferences accordingly. Archaeologists assume a mind produced the inscriptions on the Rosetta Stone. Evolutionary anthropologists argue for the intelligence of early hominids by showing that certain chipped flints are too improbably specified to have been produced by natural causes. NASA’s search for extraterrestrial intelligence (SETI) presupposed that the presence of functionally specified information imbedded in electromagnetic signals from space (such as the prime number sequence) would indicate an intelligent source.115 As yet, however, radioastronomers have not found such information-bearing signals coming from space. But closer to home, molecular biologists have identified specified complexity or informational sequences and systems in the cell, suggesting, by the same logic, an intelligent cause. Similarly, what physicists refer to as the “anthropic coincidences” constitute precisely a complex and functionally specified array of values. Given the inadequacy of the cosmological explanations based upon chance and law discussed above, and the known sufficiency of intelligent agency as a cause of specified complexity, the anthropic fine-tuning data would also seem best explained by reference to an intelligent cause.
5.2 An Argument from Ignorance?
Of course, many would object that any such arguments from evidence to design constitute arguments from ignorance. Since, these objectors say, we do not yet know how specified complexity in physics and biology could have arisen, we invoke the mysterious notion of intelligent design. On this view, intelligent design functions, not as an explanation, but as a kind of place holder for ignorance.
And yet, we often infer the causal activity of intelligent agents as the best explanation for events and phenomena. As Dembski has shown,116 we do so rationally, according to clear theoretic criteria. Intelligent agents have unique causal powers that nature does not. When we observe effects that we know from experience only intelligent agents produce, we rightly infer the antecedent presence of a prior intelligence even if we did not observe the action of the particular agent responsible.117 When these criteria are present, as they are in living systems and in the contingent features of physical law, design constitutes a better explanation than either chance and/or deterministic natural processes.
While admittedly the design inference does not constitute a proof (nothing based upon empirical observation can), it most emphatically does not constitute an argument from ignorance. Instead, the design inference from biological information constitutes an “inference to the best explanation.”118 Recent work on the method of “inference to the best explanation”119 suggests that we determine which among a set of competing possible explanations constitutes the best one by assessing the causal powers of the competing explanatory entities. Causes that can produce the evidence in question constitute better explanations of that evidence than those that do not. In this essay, I have evaluated and compared the causal efficacy of three broad categories of explanation — chance, necessity (and chance and necessity combined), and design—with respect to their ability to produce large amounts of specified complexity or information content. As we have seen, neither explanations based upon chance nor those based upon necessity, nor (in the biological case) those that combine the two, possess the ability to generate the large amounts of specified complexity or information content required to explain either the origin of life or the origin of the anthropic fine tuning. This result comports with our ordinary and uniform human experience. Brute matter — whether acting randomly or by necessity — does not have the capability to generate novel information content or specified complexity.
Yet it is not correct to say that we do not know how specified complexity or information content arises. We know from experience that conscious intelligent agents can and do create specified information-rich sequences and systems. Furthermore, experience teaches that whenever large amounts of specified complexity or information content are present in an artifact or entity whose causal story is known, invariably creative intelligence — design — has played a causal role in the origin of that entity. Thus, when we encounter such information in the biomacromolecules necessary to life, or in the fine tuning of the laws of physics, we may infer based upon our present knowledge of established cause-effect relationships that an intelligent cause operated in the past to produce the specified complexity or information content necessary to the origin of life.
Thus, we do not infer design out of ignorance but because of what we know about the demonstrated causal powers of natural entities and agency, respectively. We infer design using the standard uniformitarian method of reasoning employed in all historical sciences. These inferences are no more based upon ignorance than well-grounded inferences in geology, archeology, or paleontology are — where provisional knowledge of cause-effect relationships derived from present experience guides inferences about the causal past. Recent developments in the information sciences merely help formalize knowledge of these relationships, allowing us to make inferences about the causal histories of various artifacts, entities, or events based upon the complexity and information-theoretic signatures they exhibit.120 In any case, present knowledge of established cause-effect relationships, not ignorance, justifies the design inference as the best explanation for the origin of specified complexity in both physics and biology.
5.3 Intelligent Design: A Vera Causa?
Of course, many would admit that both biological organisms and the contingent features of physical laws manifest complexity and specificity. Nevertheless, they would argue that we cannot infer intelligent design from the presence of complexity and specificity in objects that antedate the origin of human beings. Such critics argue that we may justifiably infer a past human intelligence operating (within the scope of human history) from a specified and complex (that is, information-rich) artifact or event, but only because we already know that intelligent human agents exist. But, such critics argue, since we do not know whether an intelligent agent existed prior to humans, inferring the action of a designing mind antedating the advent of humans cannot be justified, even if we know of specified information-rich effects that clearly preexist the origin of human beings.
Note, however, that many well-accepted design inferences do not depend on prior knowledge of a designing intelligence in close spatial or temporal proximity to the effect in question. SETI researchers, for example, do not already know whether an extraterrestrial intelligence exists. Yet they assume that the presence of a large amount of specified complexity (such as the first one hundred prime numbers in sequence) would establish the existence of one. SETI seeks precisely to establish the existence of other intelligences in an unknown domain. Similarly, anthropologists have often revised their estimates for the beginning of human history or civilization because they discovered complex and (functionally) specified artifacts dating from times that antedated their previous estimates for the origin of Homo sapiens. Most inferences to design establish the existence or activity of a mental agent operating in a time or place where the presence of such agency was previously unknown. Thus, inferring the activity of a designing intelligence from a time prior to the advent of humans on earth does not have a qualitatively different epistemological status than other design inferences that critics already accept as legitimate.
Yet some would still insist that we cannot legitimately postulate such an agent as an explanation for the origin of specified complexity in life since living systems, as organisms rather than simple machines, far exceed the complexity of systems designed by human agents. Thus, such critics argue, invoking an intelligence similar to that which humans possess would not suffice to explain the exquisite complexity of design present in biological systems. To explain that degree of complexity would require a “superintellect” (to use Fred Hoyle’s phrase). Yet, since we have no experience or knowledge of such a super-intelligence, we cannot invoke one as a possible cause for the origin of life. Indeed, we have no knowledge of the causal powers of such a hypothetical agent.
This objection derives from the so-called vera causa principle — an important methodological guideline in the historical sciences. The vera causa principle asserts that historical scientists seeking to explain an event in the distant past (such as the origin of life) should postulate (or prefer in their postulations) only causes that are sufficient to produce the effect in question and that are known to exist by observation in the present.121 Darwin, for example, marshaled this methodological consideration as a reason for preferring his theory of natural selection over special creation. Scientists, he argued, can observe natural selection producing biological change; they cannot observe God creating new species.122
Even so, Darwin admitted that he could not observe natural selection creating the kind of large-scale morphological changes that his theory required. For this reason, he had to extrapolate beyond the known causal powers of natural selection to explain the origin of morphological novelty during the history of life. Since natural selection was known to produce small-scale changes in a short period of time, he reasoned that it might plausibly produce large-scale changes over vast periods of time.123 Historical scientists have long regarded such extrapolations as a legitimate way of generating possible explanatory hypotheses in accord with the vera causa principle.124
Yet, if one admits such reasoning as a legitimate extension of the vera causa principle for evolutionary arguments, it seems difficult to exclude consideration of the design hypothesis — indeed, even a theistic design hypothesis — using the same logic. Humans do have knowledge of intelligent agency as causal entity. Moreover, intelligent agents do have the ability to produce specified complexity. Thus, intelligent agency qualifies as a known cause with known causal powers sufficient to produce a specific effect (namely, specified complexity in DNA) in need of explanation. Granted we do not have direct knowledge of a nonhuman intelligence (at least, not of one with capacities greater than our own) operating in the remote past. Yet neither did Darwin have direct knowledge of natural selection operating in the past, nor did he have direct knowledge of natural selection producing large-scale morphological changes in the present. Instead, Darwin postulated a cause for the origin of morphological innovation that resembled one that he could observe in the present but which exceeded what he could observe about that cause in the magnitude of its efficacy. Using a similar logic, one might postulate the past activity of an intelligence similar to human intelligence in its rationality but greater than human intelligence in its design-capacity in order to explain the extreme sophistication and complexity of design present in biological systems. Such a postulation would, like Darwin’s, constitute an extrapolation from what we know directly about the powers of a causal entity, in this case, human intelligence. But it would not violate the vera causa principle any more than Darwin’s extrapolation did.
5.4 But Is It Science?
Of course, many simply refuse to consider the design hypothesis on the grounds that it does not qualify as “scientific”. Such critics affirm an extraevidential principle known as “methodological naturalism”.125 Methodological naturalism (MN) asserts that for a hypothesis, theory, or explanation to qualify as “scientific” it must invoke only naturalistic or materialistic causes. Clearly, on this definition, the design hypothesis does not qualify as “scientific”. Yet, even if one grants this definition, it does not follow that some nonscientific (as defined by MN) or metaphysical hypothesis may not constitute a better, more causally adequate, explanation. Indeed, this essay has argued that, whatever its classification, the design hypothesis does constitute a better explanation than its naturalistic rivals for the origin of specified complexity in both physics and biology. Surely, simply classifying this argument as metaphysical does not refute it. In any case, methodological naturalism now lacks a compelling justification as a normative definition of science. First, attempts to justify methodological naturalism by reference to metaphysically neutral (that is, non-question begging) demarcation criteria have failed.126 (See Appendix, pp. 151–211, “The Scientific Status of Intelligent Design”.) Second, asserting methodological naturalism as a normative principle for all of science has a negative effect on the practice of certain scientific disciplines. In origin-of-life research, methodological naturalism artificially restricts inquiry and prevents scientists from seeking the most truthful, best, or even most empirically adequate explanation. The question that must be asked about the origin of life is not “Which materialistic scenario seems most adequate?” but “What actually caused life to arise on earth?” Clearly, one of the possible answers to this latter question is “Life was designed by an intelligent agent that existed before the advent of humans.” Yet if one accepts methodological naturalism as normative, scientists may not consider this possibly true causal hypothesis. Such an exclusionary logic diminishes the claim to theoretical superiority for any remaining hypothesis and raises the possibility that the best “scientific” explanation (as defined by methodological naturalism) may not, in fact, be the best. As many historians and philosophers of science now recognize, evaluating scientific theories is an inherently comparative enterprise. Theories that gain acceptance in artificially constrained competitions can claim to be neither “most probably true” nor “most empirically adequate”. Instead, at best they can achieve the status of the “most probably true or adequate among an artificially limited set of options”. Openness to the design hypothesis, therefore, seems necessary to a fully rational historical biology — that is, to one that seeks the truth “no holds barred”.127
5.5 Conclusion
For almost 150 years many scientists have insisted that “chance and necessity” — happenstance and law — jointly suffice to explain the origin of life and the features or the universe necessary to sustain it. We now find, however, that materialistic thinking — with its reliance upon chance and necessity — has failed to explain the specificity and complexity of both the contingent features of physical law and the biomacromolecules upon which life depends. Even so, many scientists insist that to consider another possibility would constitute a departure from both science and reason itself. Yet ordinary reason, and much scientific reasoning that passes under the scrutiny of materialist sanction, not only recognizes but requires us to recognize the causal activity of intelligent agents. The sculptures of Michelangelo, the software of the Microsoft corporation, the inscribed steles of Assyrian kings — each bespeaks the prior action of intelligent agents. Indeed, everywhere in our high-tech environment, we observe complex events, artifacts, and systems that impel our minds to recognize the activity of other minds — minds that communicate, plan, and design. But to detect the presence of mind, to detect the activity of intelligence in the echo of its effects, requires a mode of reasoning — indeed, a form of knowledge — the existence of which science, or at least official biology, has long excluded. Yet recent developments in the information sciences now suggest a way to rehabilitate this lost way of knowing. Perhaps, more importantly, evidence from biology and physics now strongly suggests that mind, not just matter, played an important role in the origin of our universe and in the origin of the life that it contains.
Notes
- W. A. Dembski, The Design Inference: Eliminating Chance through Small Probabilities, Cambridge Studies in Probability, Induction, and Decision Theory (Cambridge: Cambridge University Press, 1998), pp. 1–35.
- The term information content is variously used to denote both specified complexity and unspecified complexity. This essay will use the term to denote the presence of both complexity and specificity. This will prove important to the argument of this essay because a sequence of symbols that is merely complex but not specified (such as “wnsgdtej3dmzcknvcnpd”) does not, on Dembski’s theory, necessarily indicate the activity of a designing intelligence. Thus, it might be argued that design arguments based upon the presence of information content commit a fallacy of equivocation by inferring design from a type of “information” (i.e., unspecified information) that could result from random natural processes. One can eliminate this ambiguity, however, by defining information content as equivalent to the joint properties of complexity and specification. Though the term is not used this way universally in classical information theory (where the term information can refer to mere improbability or complexity without necessarily implying specificity), biologists have used it to denote both complexity and specificity since the late 1950s. Indeed, Francis Crick and others equated “biological information” not only with complexity but also with what they called “specificity”—where they understood specificity to mean “necessary to function” (A. Sarkar, “Biological Information: A Skeptical Look at Some Central Dogmas of Molecular Biology”, in The Philosophy and History of Molecular Biology: New Perspectives, ed. S. Sarkar, Boston Studies in the Philosophy of Science [Dordrecht, Netherlands, 1996], 191).
- Specified complexity is not isomorphic, however, with the terms “Shannon information”, “information carrying capacity”, or “syntactic information”, as defined by classical information theory. Though Shannon’s theory and equations provided a powerful way to measure the amount of information that could be transmitted across a communication channel, it had important limits. In particular, it did not, and could not, distinguish merely improbable sequences of symbols from those that conveyed a message or a functionally specified sequence. As Warren Weaver made clear in 1949, “the word information in this theory is used in a special mathematical sense that must not be confused with its ordinary usage. In particular, information must not be confused with meaning” (C. E. Shannon and W. Weaver, The Mathematical Theory of Communication[Urbana, Ill.: University of Illinois Press, 1949], p. 8). Information theory could measure the “information-carrying capacity” or the “syntactic information” of a given sequence of symbols but could not distinguish the presence of a meaningful or functional arrangement of symbols from a random sequence (e.g., “we hold these truths to be self-evident” v. “ntnyhiznlhteqkhgdsjh”). Thus, Shannon information theory could quantify the amount of functional or meaningful information that might be present in a given sequence of symbols or characters, but it could not distinguish the status of a functional or message-bearing text from random gibberish. In essence, therefore, Shannon’s theory provided a measure of complexity or improbability but remained silent upon the important question of whether a sequence of symbols is functionally specified or meaningful.
- K. Giberson, “The Anthropic Principle”, Journal of Interdisciplinary Studies 9 (1997): 63–90, and response by Steven Yates, pp. 91–104.
- P. Davies, The Cosmic Blueprint (New York: Simon and Schuster, 1988), p.203.
- G. Greenstein, The Symbiotic Universe: Life and Mind in the Cosmos (New York: Morrow, 1988), pp. 26–27.
- Greenstein himself does not favor the design hypothesis. Instead, he favors the so-called “participatory universe principle” or “PAP”. PAP attributes the apparent design of the fine tuning of the physical constants to the universe’s (alleged) need to be observed in order to exist. As he says, the universe “brought forth life in order to exist . . . that the very Cosmos does not exist unless observed” (ibid., p. 223).
- F. Hoyle, “The Universe: Past and Present Reflections”, Annual Review of Astronomy and Astrophysics 20 (1982): 16.
- W. Craig, “Cosmos and Creator”, Origins & Design 20, no. 2 (spring 1996):23.
- J. Leslie, “Anthropic Principle, World Ensemble, Design”, American Philosophical Quarterly 19, no. 2 (1982): 150.
- P. Davies, The Superforce: The Search for a Grand Unified Theory of Nature(New York: Simon and Schuster, 1984), p. 243.
12 D. Halliday, R. Resnick, and G. Walker, Fundamentals of Physics, 5th ed. (New York: John Wiley and Sons, 1997), p. A23.
13 J. Barrow and F. Tipler, The Anthropic Cosmological Principle (Oxford: Oxford University Press, 1986), pp. 295–356, 384–444, 510–56; J. Gribbin and M. Rees, Cosmic Coincidences (London: Black Swan, 1991), pp. 3–29, 241–69; H. Ross, ” The Big Bang Model Refined by Fire”, in W. A. Dembski, ed., Mere Creation: Science, Faith and Intelligent Design (Downers Grove, Ill.: InterVarsity Press, 1998), pp. 372–81.
14 A. Guth and M. Sher, “Inflationary Universe: A Possible Solution to the Horizon and Flatness Problems”, Physical Review 23, no. 2 (1981): 348.
15 For those unfamiliar with exponential notation, the number 1060 is the same as 10 multiplied by itself 60 times or 1 with 60 zeros written after it.
16 P. Davies, God and the New Physics (New York: Simon and Schuster, 1983), p. 188.
17 R. Penrose, The Emperor’s New Mind (New York: Oxford, 1989), p. 344.
32 Behe, Darwin’s, pp. 165–86.
18 A. Linde, “The Self–Reproducing Inflationary Universe”, Scientific American 271 (November 1994): 48–55.
33 W. A. Dembski, Intelligent Design: The Bridge between Science and Theology(Downers Grove, Ill.: InterVarsity Press, 1999), pp. 146–49.
19 C. Longley, “Focusing on Theism”, London Times, January 21, 1989, p.10.
34 F. Sanger and H. Tuppy, “The Amino Acid Sequence in the Phenylalanyl Chain of Insulin, 1 and 2″, Biochemical Journal 49 (1951): 463–80; F. Sanger and E. O. P. Thompson, ” The Amino Acid Sequence in the Glycyl Chain of Insulin. 1: The Identification of Lower Peptides from Partial Hydrolysates”,Biochemical Journal 53 (1953): 353–74; H. Judson, Eighth Day of Creation (New York: Simon and Schuster, 1979), pp. 213, 229–35, 255–61, 304, 334–35.
20 W. Craig, “Barrow and Tipler on the Anthropic Principle v. Divine Design”, British Journal for the Philosophy of Science 38 (1988): 389–95.
21 J. W. Richards, “Many Worlds Hypotheses: A Naturalistic Alternative to Design”, Perspectives on Science and Christian Belief 49, no. 4 (1997): 218–27.
22 R. Collins, “The Fine-Tuning Design Argument: A Scientific Argument for the Existence of God”, in M. Murray, ed., Reason for the Hope Within (Grand Rapids, Mich.: Eerdmans, 1999), p. 61.
35 J. C. Kendrew, G. Bodo, H. M. Dintzis, R. G. Parrish, and H. Wyckoff, “A Three-Dimensional Model of the Myoglobin Molecule Obtained by X-Ray Analysis”, Nature 181 (1958): 664–66; Judson, Eighth Day, pp. 562–63.
23 Ibid., pp. 60–61.
24 Craig, “Cosmos”, p. 24.
25 R. Swinburne, “Argument from the Fine Tuning of Universe”, in J. Leslie,
36 B. Alberts, D. Bray, J. Lewis, M. Raff, K. Roberts, and J. D. Watson,Molecular Biology of the Cell (New York: Garland, 1983), pp. 91–141.
ed., Physical Cosmology and Philosophy (New York: Macmillan, 1990), pp. 154–73.
38 J. Watson and F. Crick, “A Structure for Deoxyribose Nucleic Acid”,Nature 171 (1953): 737–38.
26 Originally the many-worlds hypothesis was proposed for strictly scientific reasons as a solution to the so-called quantum-measurement problem in physics. Though its efficacy as an explanation within quantum physics remains controversial among physicists, its use there does have an empirical basis. More recently, however, it has been employed to serve as an alternative non-theistic explanation for the fine tuning of the physical constants. This use of the MWH does seem to betray a metaphysical desperation.
39 Ibid.; J. Watson and F. Crick, “Genetical Implications of the Structure of Deoxyribose Nucleic Acid”, Nature 171 (1953): 964–67.
27 Longley, “Focusing”, p. 10.
especially K. Dose, “The Origin of Life: More Questions than Answers”, Interdisciplinary Science Review 13, no. 4 (1998): 348–56; H. P. Yockey, Information Theory and Molecular Biology (Cambridge: Cambridge University Press, 1992), pp. 259–93; C. Thaxton, W. Bradley, and R. Olsen, The Mystery of Life’s Origin(Dallas: Lewis and Stanley, 1992); C. Thaxton and W. Bradley, “Information and the Origin of Life”, in The Creation Hypothesis: Scientific Evidence for an Intelligent Designer, ed. J. P. Moreland (Downers Grove, Ill.: InterVarsity Press,1994), pp. 173–210; R. Shapiro, Origins (London: Heinemann, 1986), pp. 97–189; S.C. Meyer, “The Explanatory Power of Design: DNA and the Origin of Information”, in Dembski, Mere Creation, pp. 119–34. For a contradictory hypothesis, see S. Kauffman, The Origins of Order (Oxford: Oxford University Press, 1993), pp. 287–341.
28 J. Polkinghorne, “So Finely Tuned a Universe of Atoms, Stars, Quanta & God”, Commonweal, August 16, 1996, p. 16.
29 B. Alberts, “The Cell as a Collection of Protein Machines: Preparing the Next Generation of Molecular Biologists”, Cell 92 (February 8, 1998): 291.
30 M. Behe, Darwin’s Black Box (New York: Free Press, 1996), pp. 51–73.
31 According to the neo-Darwinian theory of evolution, organisms evolved by natural selection acting on random genetic mutations. If these genetic mutations help the organism to survive better, they will be preserved in subsequent generations, while those without the mutation will die off faster. For instance, a Darwinian might hypothesize that giraffes born with longer necks were able to reach the leaves of trees more easily, and so had greater survival rates, than giraffes with shorter necks. With time, the necks of giraffes grew longer and longer in a step-by-step process because natural selection favored longer necks. But the intricate machine-like systems in the cell could not have been selected in such a step-by-step process, because not every step in the assembly of a molecular machine enables the cell to survive better. Only when the molecular machine is fully assembled can it function and thus enable a cell to survive better than cells that do not have it.
45 G. Wald, “The Origin of Life”, Scientific American 191 (August 1954):44–53; Shapiro, Origins, p. 121.
37 Judson, Eighth Day, p. 611.
40 Judson, Eighth Day, pp. 245–46.
41 Ibid., pp. 335–36.
42 R. Dawkins, River out of Eden (New York: Basic Books, 1995), p. 10.
43 B. Gates, The Road Ahead (Boulder, Col.: Blue Penguin, 1996), p. 228.44 For a good summary and critique of different naturalistic models, see
46 F. Crick, “The Origin of the Genetic Code”, Journal of Molecular Biology38 (1968): 367–79; H. Kamminga, Studies in the History of Ideas on the Origin of Life (Ph.D. diss., University of London, 1980), pp. 303–4.
47 C. de Duve, Blueprint for a Cell: The Nature and Origin of Life (Burlington, N.C.: Neil Patterson Publishers, 1991), p. 112; F. Crick, Life Itself (New York:
106 stephen c. meyer
evidence for design in physics and biology 107
Simon and Schuster, 1981), pp. 89–93; H. Quastler, The Emergence of Biological Organization (New Haven: Yale University Press, 1964), p. 7.
effectively limits the probabilistic resources available to explain the origin of specified biological information (ibid., 1998, pp. 175–229).
48 H. J. Morowitz, Energy Flow in Biology (New York: Academic Press, 1968), pp. 5–12.
60 Cassette mutagenesis experiments have usually been performed on proteins of about one hundred amino acids in length. Yet extrapolations from these results can generate reasonable estimates for the improbability of longer protein molecules. For example, Sauer’s results on the proteins lambda repressor and arc repressor suggest that, on average, the probability at each site of finding an amino acid that will maintain functional sequencing (or, more accurately, that will produce folding) is less than 1 in 4 (1 in 4.4). Multiplying 1/4 by itself 150 times (for a protein 150 amino acids in length) yields a probability of roughly 1 chance in 1091. For a protein of that length the probability of attaining both exclusive peptide bonding and homochirality is also about 1chance in 1091. Thus, the probability of achieving all the necessary conditions of function for a protein 150 amino acids in length exceeds 1 chance in 10180.
49 F. Hoyle and C. Wickramasinghe, Evolution from Space (London: J. M. Dent, 1981), pp. 24–27.
50 A. G. Cairns–Smith, The Life Puzzle (Edinburgh: Oliver and Boyd, 1971), pp. 91–96.
51 I. Prigogine, G. Nicolis, and A. Babloyantz, “Thermodynamics of Evolution”, Physics Today, November 1972, p. 23.
52 Yockey, Information Theory, pp. 246–58; H. P. Yockey, “Self Organization, Origin of Life Scenarios and Information Theory”, Journal of Theoretical Biology 91 (1981): 13–31; see also Shapiro, Origins, pp. 117–31.
53 Prigogine, Nicolis, and Babloyantz, “Thermodynamics”, p. 23.
54 Cairns-Smith, Life Puzzle, p. 95.
55 Alberts et al., Molecular Biology, p. 118.
56 Actually, Sauer counted sequences that folded into stable three-dimen-
61 Dembski, Design Inference, pp. 67–91, 175–214; cf. E. Borel, Probabilities and Life, trans. M. Baudin (New York: Dover, 1962), p. 28.
sional configurations as functional, though many sequences that fold are not functional. Thus, his results actually underestimate the probabilistic difficulty.57 J. Reidhaar-Olson and R. Sauer, “Functionally Acceptable Solutions in Two Alpha-Helical Regions of Lambda Repressor”, Proteins, Structure, Function, and Genetics 7 (1990): 306–10; J. Bowie and R. Sauer, “Identifying Determinants of Folding and Activity for a Protein of Unknown Sequences: Tolerance to Amino Acid Substitution”, Proceedings of the National Academy of Sciences,USA 86 (1989): 2152–56; J. Bowie, J. Reidhaar-Olson, W. Lim, and R. Sauer, “Deciphering the Message in Protein Sequences: Tolerance to Amino Acid Substitution”, Science 247 (1990): 1306–10; M. Behe, “Experimental Support for Regarding Functional Classes of Proteins to Be Highly Isolated from Each Other”, in J. Buell and G. Hearns, eds., Darwinism: Science or Philosophy? (Dallas: Haughton Publishers, 1994), pp. 60–71; Yockey, Information Theory, pp.
62 E. Pennisi, “Seeking Life’s Bare Genetic Necessities”, Science 272 (1996):1098–99; A. Mushegian and E. Koonin, “A Minimal Gene Set for Cellular Life Derived by Comparison of Complete Bacterial Genomes”, Proceedings of the National Academy of Sciences, USA 93 (1996): 10268–73; C. Bult et al., “Complete Genome Sequence of the Methanogenic Archaeon, Methanococcus Jannaschi”, Science 273 (1996): 1058–72.
246–58.
58 See also D. Axe, N. Foster, and A. Ferst, “Active Barnase Variants with
Yale University Press, 1964), p. 7.
69 A. I. Oparin, The Origin of Life, trans. S. Morgulis (New York: Macmillan
Completely Random Hydrophobic Cores”, Proceedings of the National Academy of Sciences, USA 93 (1996): 5590.
Co., 1938), pp. 64–103; S. C. Meyer, Of Clues and Causes: A Methodological Interpretation of Origin of Life Studies (Ph.D. diss., Cambridge University, 1991), pp. 174–79, 194–98, 211–12.
59 W. Dembski, The Design Inference: Eliminating Chance through Small Probabilities (Cambridge: Cambridge University Press, 1998), pp. 67–91, 175–223. Dembski’s universal probability bound actually reflects the “specificational” resources, not the probabilistic resources, in the universe. Dembski’s calculation determines the number of specifications possible in finite time. It nevertheless has the effect of limiting the “probabilistic resources” available to explain the origin of any specified event of small probability. Since living systems are precisely specified systems of small probability, the universal probability bound
70 Oparin, Origin, pp. 107–8.71 Ibid., pp. 133–35.
72 Ibid., pp. 148–59.
73 Ibid., pp. 195–96.
63 Dembski, Design Inference, pp. 67–91, 175–223.
64 P.T. Mora, “Urge and Molecular Biology”, Nature 199 (1963): 212–19.65 I. Hacking, The Logic of Statistical Inference (Cambridge: Cambridge Uni-
versity Press, 1965), pp. 74–75.
66 Dembski, Design Inference, pp. 47–55.
67 C. de Duve, “The Beginnings of Life on Earth”, American Scientist 83
(1995): 437.
68 H. Quastler, The Emergence of Biological Organization (New Haven, Conn.:
74 A. I. Oparin, Genesis and Evolutionary Development of Life (New York: Academic Press, 1968), pp. 146–47.
75 De Duve, Blueprint, p. 187.
108 stephen c. meyer
evidence for design in physics and biology 109
76 G. Joyce and L. Orgel, “Prospects for Understanding the Origin of the RNA World”, in R. F. Gesteland and J. F. Atkins, eds., RNA World (Colds Spring Harbor, N.Y.: Colds Spring Harbor Laboratory Press, 1993), pp. 8–13.
94 Kauffman, Origins, pp. 285–341.
77 J. von Neumann, Theory of Self-Reproducing Automata, ed. and completed by A. Berks (Urbana, Ill.: University of Illinois Press, 1966).
96 D. Kenyon, foreword to C. Thaxton, W. Bradley, and R. Olsen, The Mystery of Life’s Origin (Dallas: Lewis and Stanley, 1992), pp. v–viii; D. Kenyon and G. Mills, “The RNA World: A Critique”, Origins & Design 17, no. 1 (1996):12–16; D. Kenyon and P. W. Davis, Of Pandas and People: The Central Question of Biological Origins (Dallas: Haughton, 1993); S. C. Meyer, “A Scopes Trial for the ’90’s”, The Wall Street Journal, December 6, 1993, p. A14; Kok, Taylor, and Bradley, “Examination”, pp. 135–42.
78 E. Wigner, “The Probability of the Existence of a Self-Reproducing Unit”, in The Logic of Personal Knowledge: Essays Presented to Michael Polanyi on His Seventieth Birthday (London: Routledge and Paul, 1961), pp. 231–35.
79P.T.Landsberg,”DoesQuantumMechanicsExcludeLife?”Nature302(1964): 928–30.
80 H. J. Morowitz, “The Minimum Size of the Cell”, in M. O’Connor and G. Wolstenholme, eds., Principles of Biomolecular Organization (London: Churchill, 1966), pp. 446–59; Morowitz, Energy, pp. 10–11.
97 Steinman and Cole, “Synthesis”, pp. 735–41; Steinman, “Sequence Generation”, pp. 533–39.
81 T. Dobzhansky, discussion of G. Schramm’s paper, in S. W. Fox, ed., The Origins of Prebiological Systems and of Their Molecular Matrices (New York: Academic Press, 1965), p. 310; see also H. H. Pattee, ” The Problem of Biological Hierarchy”, in C. H. Waddington, ed., Toward a Theoretical Biology, vol. 3 (Edinburgh: Edinburgh University Press, 1970), p. 123.
98 Kok, Taylor, and Bradley, “Examination”, pp. 135–42.
99 Alberts et al., Molecular Biology, p. 105.
100 Ku ̈ppers, “Prior Probability”, p. 364.
101 Note that the “RNA world” scenario was not devised to explain the ori-
82 P. T. Mora, “The Folly of Probability”, in Fox, Origins, pp. 311–12; L. V. Bertalanffy, Robots, Men and Minds (New York: George Braziller, 1967), p. 82.83 R. Dawkins, The Blind Watchmaker (London: Longman, 1986), pp. 47–
gin of the sequence specificity of biomacromolecules. Rather it was proposed as an explanation for the origin of the interdependence of nucleic acids and proteins in the cellular information processing system. In extant cells, building proteins requires instructions from DNA, but information on DNA cannot be processed without many specific proteins and protein complexes. This poses a “chicken-or-egg” dilemma. The discovery that RNA (a nucleic acid) possesses limited catalytic properties (as modern proteins do) suggested a way to split the horns of this dilemma. By proposing an early earth environment in which RNA performed both the enzymatic functions of modern proteins and the information storage function of modern DNA, “RNA first” advocates sought to formulate a scenario making the functional interdependence of DNA and proteins unnecessary to the first living cell. In so doing, they sought to make the origin of life a more tractable problem from a chemical evolutionary point of view. In recent years, however, many problems have emerged with the RNA world (Shapiro, Origins, pp. 71–95; Kenyon, “RNA World”, pp. 9–16). To name just one, RNA possesses very few of the specific catalytic properties necessary to facilitate the expression of the genetic information on DNA. In any case, by addressing a separate problem, the RNA world presupposed a solution to, but did not solve, the sequence specificity or information problem. A recent article heralding a breakthrough for “RNA world” scenarios makes this clear. After reporting on RNA researcher Jack Szostak’s successful synthesis of RNA molecules with some previously unknown catalytic properties, science writer John Horgan makes a candid admission: “Szostak’s work leaves a major question unanswered: How did RNA, self-catalyzing or not, arise in the first place?” (J.Horgan,”TheWorldaccordingtoRNA”,ScientificAmerican,January1996, p. 27; R. Shapiro, “Prebiotic Ribose Synthesis: A Critical Analysis”, Origins of Life and Evolution of the Biosphere 18 [1988]: 71–95; A. Zaug and T. Cech, “The
49. 84 B. Ku ̈ppers, “The Prior Probability of the Existence of Life”, in L. Kru ̈ ger, G. Gigerenzer, and M. S. Morgan, (Cambridge: MIT Press, 1987), pp. 355–69. eds., The Probabilistic Revolution
85 Ibid., p. 366.
86 Ibid.
87 Dawkins, Watchmaker, pp. 47–49.
88 P. Nelson, “Anatomy of a Still-Born Analogy”, Origins & Design 17, no.
3 (1996): 12.
89 De Duve, “Beginnings”, p. 437.
90 Morowitz, Energy, pp. 5–12.
91 G. Steinman and M. N. Cole, “Synthesis of Biologically Pertinent Pep-
tides under Possible Primordial Conditions”, Proceedings of the National Academy of Sciences, USA 58 (1967): 735–41; G. Steinman, “Sequence Generation in Prebiological Peptide Synthesis”, Archives of Biochemistry and Biophysics 121 (1967):533–39; R. A. Kok, J. A. Taylor, and W. L. Bradley, “A Statistical Examination of Self-Ordering of Amino Acids in Proteins”, Origins of Life and Evolution of the Biosphere 18 (1988): 135–42.
92 D. Kenyon and G. Steinman, Biochemical Predestination (New York: McGraw-Hill, 1969), pp. 199–211, 263–66.
93 I. Prigogine and G. Nicolis, Self-Organization in Nonequilibrium Systems(New York: John Wiley, 1977), pp. 339–53, 429–47.
95 De Duve, “Beginnings”, pp. 428–37; C. de Duve, Vital Dust: Life as a Cosmic Imperative (New York: Basic Books, 1995).
110 stephen c. meyer
evidence for design in physics and biology 111
Intervening Sequence RNA of Tetrahymena Enzyme”, Science 231 [1986]: 470–75; T. Cech, “Ribozyme Self-Replication?” Nature 339 [1989] 507–8; Kenyon, “RNA World”, pp. 9–16).
115 T. R. McDonough, The Search for Extraterrestrial Intelligence: Listening for Life in the Cosmos (New York: Wiley, 1987).
102 De Duve, “Beginnings”, p. 437.
116 Dembski, Design Inference, pp. xi–xiii, 1–35.
117 Ibid., pp. 1–35, 36–66.
118 P. Lipton, Inference to the Best Explanation (New York: Routledge, 1991),
103 This, in fact, happens where adenine and thymine do interact chemically in the complementary base pairing across the message-bearing axis of the DNA molecule. Recent experiments have also shown that deoxyribonucleoside 5′ triphosphates (i.e., the nucleotide bases joined with necessary sugar and phosphate molecules) will form repetitive sequences in solution even when polymerization is facilitated by a polymerizing enzyme such as DNA polymerase (N. Ogata and T. Miura, “Genetic Information ‘Created’ by Archaebacterial DNA Polymerase”, Biochemistry Journal 324 [1997]: 567–71).
pp. 32–88.
119 Ibid.; S. C. Meyer, “The Methodological Equivalence of Design and De-
104 M. Polanyi, “Life’s Irreducible Structure”, Science 160 (1968): 1308–12, esp. 1309.
120 Dembski, Design Inference, pp. 36–66, esp. p. 37.
105 The information-carrying capacity of any symbol in a sequence is inversely related to the probability of its occurrence. The informational capacity of a sequence as a whole is inversely proportional to the product of the individual probabilities of each member in the sequence. Since chemical affinities between constituents (“symbols”) increase the probability of the occurrence of one given another (i.e., necessity increases probability), such affinities decrease the information-carrying capacity of a system in proportion to the strength and relative frequency of such affinities within the system.
121 M. J. S. Hodge, “The Structure and Strategy of Darwin’s ‘Long Argument’ “, British Journal for the History of Science 10 (1977): 239.
106F.Dretske,KnowledgeandtheFlowofInformation(Cambridge:MITPress,1981), p. 12.
ed., But Is It Science? (Buffalo, N.Y.: Prometheus Books, 1988), p. 301; R. Lewontin, “Billions and Billions of Demons”, The New York Review of Books, January 9, 1997, p. 31; Meyer, “Equivalence”, pp. 69–71.
107 Yockey, “Self Organization”, p. 18.
126 Meyer, “Laws”, pp. 29–40; Meyer, “Equivalence”, pp. 67–112; S. C. Meyer, “Demarcation and Design: The Nature of Historical Reasoning”, in Jitse van der Meer, ed., Facets of Faith and Science, vol. 4, Interpreting God’s Action in the World (Lanham, Md.: University Press of America, 1996), pp. 91–130; L. Laudan, “The Demise of the Demarcation Problem”, in Ruse, Science?, pp. 337–50; L. Laudan, “Science at the Bar—Causes for Concern”, in Ruse,Science?, pp. 351–55; A. Plantinga, “Methodological Naturalism”, Origins & Design 18, no. 1 (1997): 18–27, and no. 2 (1997): 22–34.
108 Orgel has drawn a similar distinction between either order or the randomness that characterizes inanimate chemistry and what he calls the “specified complexity” of informational biomolecules (A. I. Orgel, The Origins of Life on Earth [New York: Macmillan, 1973], pp. 189ff.; Thaxton, Mystery, pp. 130ff.).
109 H. P. Yockey, “A Calculation of the Probability of Spontaneous Biogenesis by Information Theory”, Journal of Theoretical Biology 67 (1977): 380.
110 M. Eigen, Steps toward Life (Oxford: Oxford University Press, 1992), p.12.
127 P. W. Bridgman, Reflections of a Physicist, 2d ed. (New York: Philosophical Library, 1955), p. 535.
111 Quastler, Emergence, p. 16.
112 This qualification means to acknowledge that chance can produce low levels (less than 500 bits) of specified information (see Dembski, Design Inference, pp. 175–223).
113 Meyer, Clues, pp. 77–140.
114 Ibid.; E. Sober, Reconstructing the Past (Cambridge: MIT Press, 1988), pp. 4–5; M. Scriven, “Causes, Connections, and Conditions in History”, in W. Dray, ed., Philosophical Analysis and History (New York: Harper and Row,1966), pp. 249–50.
scent: Can There Be a Scientific Theory of Creation?” in J. P. Moreland, ed.,The Creation Hypothesis: Scientific Evidence for an Intelligent Designer (Downers Grove, Ill.: InterVarsity Press, 1994), pp. 67–112; E. Sober, The Philosophy of Biology (San Francisco: Westview Press, 1993), p. 44; Meyer, Clues, pp. 77–140.
122 V. Kavalovski, The Vera Causa Principle: A Historico-Philosophical Study of a Meta-theoretical Concept from Newton through Darwin (Ph.D. diss., University of Chicago, 1974), p. 104.
123 Meyer, Clues, pp. 87–91.
124 Kavalovski, Vera Causa, p. 67.
125 M. Ruse, “Witness Testimony Sheet: McLean v. Arkansas”, in M. Ruse,